- References
- Introduction
- Storage Tiers Or Classes
- Charges
- Security
- Policies
- Encryption
- CORS Configuration
- Performance Optimization
References
Introduction
- Simple Storage Service
- Provides developers and IT teams with secure, durable, highly-scalable object storage.
- For files, images etc. not for Operating systems or databases.
- Object based storage.
- Data is spread across multiple devices and facilities.
- Files can be from 0 Bytes to 5 TB.
- Unlimited Storage.
- Files are stored in Buckets(similar to folder).
- S3 is a universal namespace ie. names must be unique globally same as DNS.
- ex. https://s3-eu-west-1.amazonaws.com/acloudguru
- HTTP 200 on successful upload for cli.
- Read after write consistency for PUTS of new objects.
- Eventual consistency for overwrite PUTS and DELETES.(can take some time to propagate).
- S3 is Object based
- Key - name of the object
- Value - the data, made up of sequence of bytes.
- Version ID
- Metadata - Data about data being stored
- Subresources - bucket specific configuration
- bucket policies, Access control list.
- Cross origin resource sharing(CORS).
- Transfer acceleration
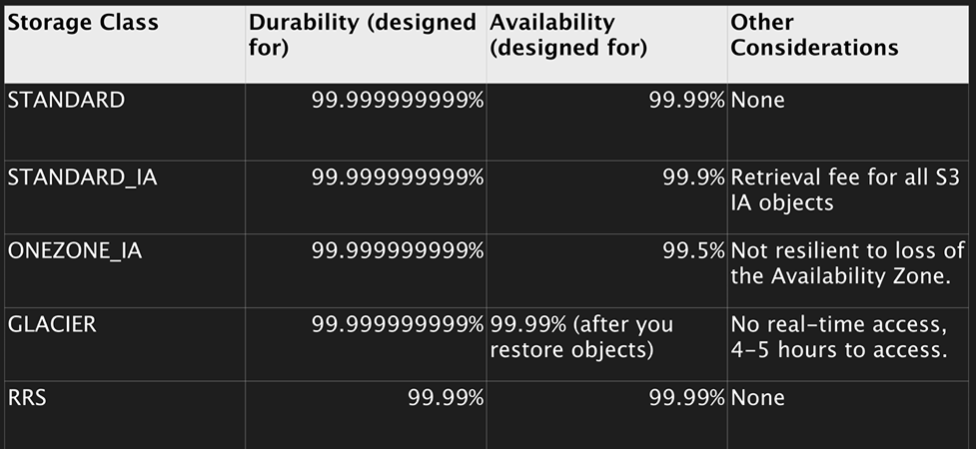
- Built for 99.99% Availability - time for which service is available
- Amazon guarantees 99.9% availability.
- Amazon guarantees 99.999999999% durability - Amount of data that will not corrupt.
- Tiered Storage
- Lifecycle management
- Versioning
- Encryption
- Secure your data - Access Control Lists and Bucket Policies
Storage Tiers Or Classes
S3
- 99.99% Availability
- 99.999999999% Durability
- Stored redundantly across multiple devices in multiple facilities.
- Designed to sustain loss of 2 facilities concurrently.
S3 IA (Infrequently Accessed)
- For data that is accessed less frequently, but requires rapid access when needed.
- Lower price than S3 but you are charged a retrieval fee.
S3 One Zone IA
- Same as IA however data is stored in a single Availability zone.
- 99.5% Availability
- 99.999999999% Durability
- Costs 20% lesser than regular S3-IA.
Reduced Redundancy Storage
- 99.99% availability and durability
- Used for data that can be created if lost, eg. thumbnails.
- Amazon suggesting to use normal S3 rather than Reduced Redundancy Storage, adjustments made in pricing
- May phase out in future
Glacier
- Very cheap
- Used for archival only
- Optimised for data that is infrequently accessed
- It takes 3-5 hours to restore from glacier.
S3 Intelligent Tiering
- Unknown or unpredictable access patterns
- 2 tiers - frequent and infrequent access
- Automatically moves your data to most cost-effective tier based on how frequently you access each object.
- frequent access tier object not accessed for 30 days –> move to infrequent tier.
- as soon as infrequent tier object is accessed, it is moved to frequent access tier.
- 99.999999999% durability
- 99.9% availability
- Optimizes cost
- No fees for accessing your data but small monthly fee for monitoring/automation $0.0025 per 1000 objects.
Charges
- Storage per GB
- Requests (Get, Put, Copy etc.)
- Storage management pricing
- INventory, Analytics, and Object tags
- Data Management Pricing
- Data transferred out of S3
- Transfer Acceleration
Security
- By default, all newly created buckets are private.
- Can setup access control to buckets using
- Bucket Policies - Applied at bucket level
- Access Control List - Applied at an object level
- S3 buckets can be configured to create access logs, which log all the requests made to the S3 bucket. These logs can be written to another bucket.
Policies
AWS --> S3 --> Shows global view of all regions --> select region --> Create bucket --> can create folders
- Enable Versioning Checkbox
- Enable Server Access Logging
- Can use tags to track project costs.
- Enable object level logging using AWS cloudTrail
- Enable Default Encryption
- AES-256 : Uses server side encryption with Amazon S3-Managed Keys (SSE-S3)
- AWS-KMS : Uses Server Side Encryption with AWS KMA-Managed Keys(SSE-KMS)
- CloudWatch request metrics
Select Folder --> upload files -->
- Set permissions
- can set encryption
Bucket Public Settings
select bucket --> Permissions -->
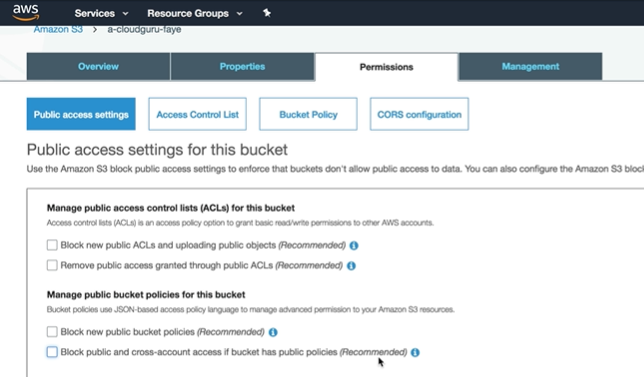
- If bucket policy is set as private, you cannot upload public objects to it.
Bucket Policy
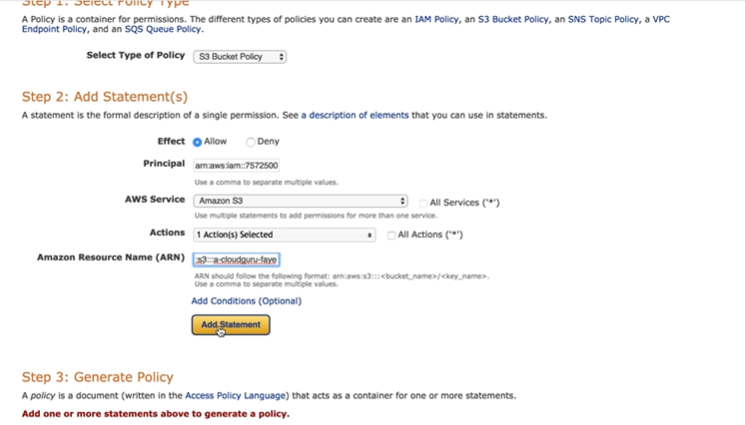
- Use policy generator to create document.
- Policy Type - SQS, S3, VPC, IAM, SNS Topic
- Effect - Allow, Deny
- Principal - User (ARN), S3 Service, AWS account number etc. (Entity for policy)
- Action - action for AWS Service
- ARN (Amazon Resource Name) - bucket ARN (target object)
- Click Add Statement to add policy statement, can add multiple statements
- Click Generate policy
- Copy paste the policy to bucket –> permissions –> bucket policy
Encryption
Types of Encryption
- Encryption In Transit
- SSL/TLS ie. https
- For data you are transferring to and from your bucket
- Encryption At Rest - Server Side Encryption
- S3 Managed Keys - SSE-S3
- AES-256, Advanced encryption standard 256 bits
- Each object encrypted with its own key using strong multifactor encryption
- Additional Step - Also encrypt the key with master key, AWS manages and rotates the keys for you.
- AWS Key Management Service, Managed Keys, SSE-KMS
- AWS managed keys with additional benefits.
- You get a Separate permission for use of an additional key called Envelope Key.
- Envelope Key encrypts yours data’s encryption key.
- You also get an audit trail for the use of your encryption keys, so you can see who used it and why.
- Server Side Encryption with customer provided keys - SSE-C
- AWS manages encryption and decryption but you manage your own keys.
- You are incharge of rotating those keys and lifecycle of those keys.
- S3 Managed Keys - SSE-S3
- Client Side Encryption
- You encrypt the files yourself before uploading to S3.
Enforcing Encryption on S3 Buckets
- Everytime a file is uploaded to S3, a PUT request is initiated.
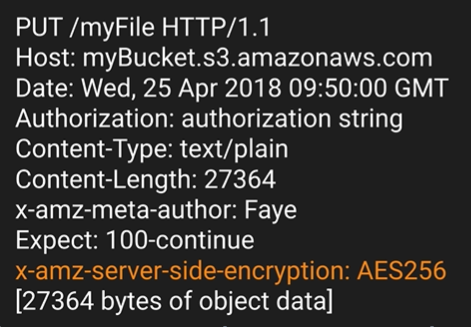
- PUT /filename HTTP/1.1
- HOst bucket dns
- Authorization
- x-amz-meta-author: Faye
- Expect: 100-continue
- Tells S3 not to send your RequestBody until recieves an acknowledgement.
- S3 can reject your request based on the contents of your header.
- If file is to be encrypted at upload time, header will have x-amz-server-side-encryption parameter.
- x-amz-server-side-encryption: AES256 (SSE-S3 - S3 managed keys)
- x-amz-server-side-encryption: ams:kms (SSE-KMS - KMS managed keys)
- Can enforce use of SSE by using bucket policy which denies any s3 PUT request which doesn’t include header param
x-amz-server-side-encryption
HTTP 100 Continue
Read more about 100 Continue
- Informational status response code indicates that everything so far is OK and that the client should continue with the request or ignore it if it is already finished.
- To have a server check the request’s headers, a client must send Expect: 100-continue as a header in its initial request and receive a 100 Continue status code in response before sending the body.
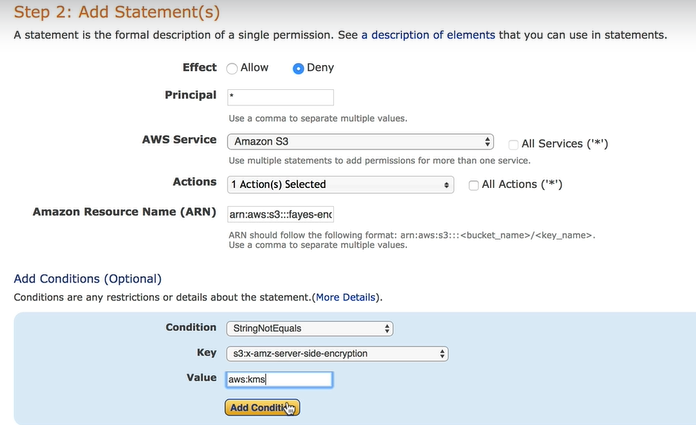

- Here add “/*” for Resource if error shows up “Action does not apply to any resource in statement”
CORS Configuration
- Cross origin resource sharing
- S3 buckets could be used to host a static website.
- create public bucket
- properties –> static website hosting
- index.html
- error.html
- to enable cors
- go to target bucket being accessed
- permissions –> CORS configuration –> update Allowed Origin
- Use Case - Static Website
- put images, js, html in different buckets
Performance Optimization
- By default, designed to support very high request rates.
- However, if S3 buckets are routinely receiving >100 PUTS/LIST/DELETE or >100 GET requests per second, then there are some best practice guidelines to optimize S3 performance.
- Guidance is based on type of workload you are running
- GET-Intensive Workloads - Use CloudFront content delivery service to get best performance. CloudFront will cache your most frequently accessed objects and will reduce latency for your GET requests.
- Mixed Request Type Workloads - a mix of GET, PUT, DELETE
- the key names being used for your objects impact performance for intensive workloads.
- S3 uses keyname to determine which partition an object will be stored in.
- Use of sequencial keynames eg. name prefixed with timestamp or alphabetical sequence increases the likelihood of having many objects stored on same partition.
- For heavy workloads this can cause I/O issues and contention.
- By using random prefix (like hex hash) to the key names, you can force S3 to distribute your keys accross multiple partitions, distributing the I/O workload.
- S3 performance updates
- 3,500 PUT requests per second
- 5.500 GET requests
- This negates the previous guidance to randomize your object names, now sequencial and logical naming patterns can used without any performance implications.