Distributed Systems
Table of contents
Topics
- A Thorough Introduction to Distributed Systems
- Data Intensive Applications - We call an application data-intensive if data is its primary challenge—the quantity of data, the complexity of data, or the speed at which it is changing—as opposed to compute-intensive, where CPU cycles are the bottleneck.
Distributed System Approaches
Master Slave
- Master Slave
- All requests goes to Master first, takes lock
- Transaction Management
- Not Scalability
Masterless
- All are Master
- Prepare intermediate result
- Intermediate results are combined to make final result
- Here Network Latency problem is observed.
Big Data Problems
- Network Latency
- Distribute data in small blocks (Map Reduce)
- Denormalization
Issues to be Figured out
Replication
- Replication refers to frequently copying the data across multiple machines.
- Post replication, multiple copies of the data exists across machines.
- This might help in case one or more of the machines die due to some failure.
Scalability
Types of Scaling
- horizontal scaling (scale out) - adding more servers.
- vertical scaling (scale up) - to increase the resources of the server (RAM, CPU, storage, etc.).
- Example: Lets say you own a restaurant which is now exceeding its seating capacity. One way of accommodating more people ( scaling ) would be to add more and more chairs (scaling vertically). However since the space is limited, you won’t be able to add more chairs once the space is full. Another way of scaling would be to open new branches of the restaurant ( horizontal scaling ).
Storage Scalability
- no design is correct or wrong, there are just good designs and bad designs which heavily depend on the use case.
- Hence, it is extremely important to clarify the requirements for the problem asked.
Pre Requisites
Have some experience working with a relational DB ( like MySQL ).
- Have a basic idea about NoSQL DBs.
- Understand the basics of the following :
- Concurrency : Do you understand threads, deadlock, and starvation? What happens when multiple processes / threads are trying to modify the same data? A basic understanding of read and write locks.
- Networking : Do you roughly understand basic networking protocols like TCP and UDP? Do you understand the role of switches and routers?
- File systems : You should understand the systems you’re building upon. Do you know roughly how an OS, file system, and database work? Do you know about the various levels of caching in a modern OS?
CAP theorem
- CAP Theorem in plain english
- CAP Theorem states that in a distributed system, either 2 of the 3 features can be guaranteed:
- Consistency
- Availability
- Partition Tolerance
- This is for data centres that are installed across multiple locations
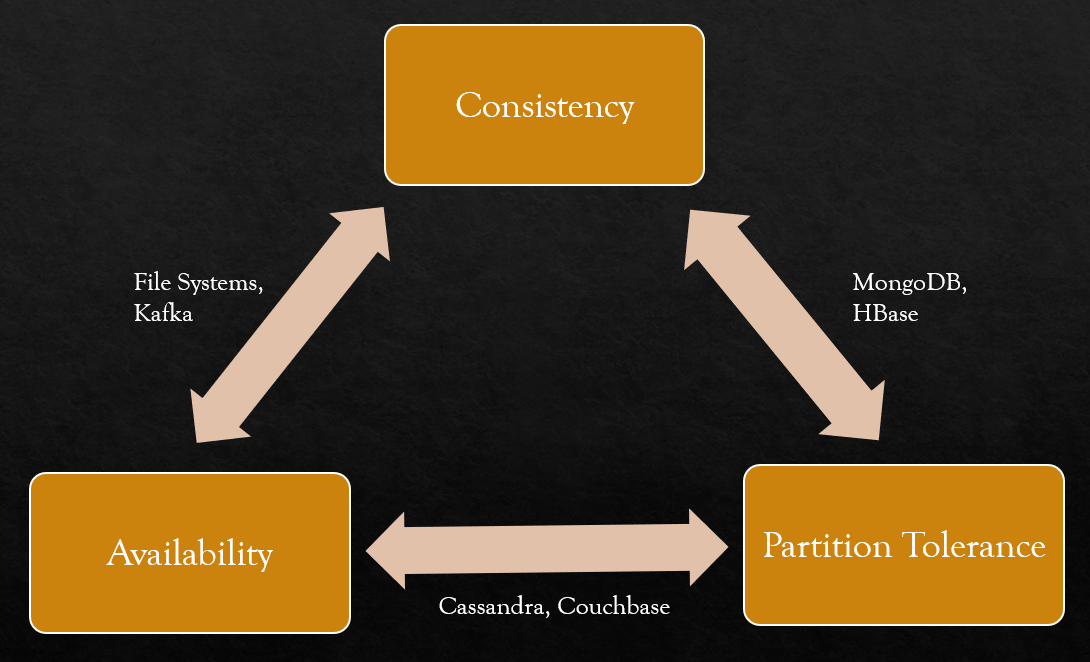
Consistency
- Consistency
- Assuming you have a storage system which has more than one machine, consistency implies that the data is same across the cluster, so you can read or write to/from any node and get the same data.
- Strongly Consistent.
- Eventual consistency
- In a cluster, if multiple machines store the same data, an eventual consistent model implies that all machines will have the same data eventually.
- Its possible that at a given instance, those machines have different versions of the same data ( temporarily inconsistent ) but they will eventually reach a state where they have the same data.
Availability
- In the context of a database cluster, Availability refers to the ability to always respond to queries ( read or write ) irrespective of nodes going down.
Partition Tolerance - Reliability
- In the context of a database cluster, cluster continues to function even if there is a “partition” (communications break) between two nodes (both nodes are up, but can’t communicate).
Efficiency
Maintainability
Data Stores
Relational Database - RDBMS
Why use RDMS at all?
- Provides ACID Properties
ACID Properties
- Atomicity - Transaction Management
- Consistency
- Isolation
- Durability
NoSQL Data Stores
- MongoDB -> Replica Set
- Transaction management is within single replica set not accross multiple replica sets.
- Casandra -> Partition
- Transaction management is possible only if in the same partition only.
- Redundancy is not a problem then use NoSQL otherwise RDBMS.
Sharding
- With most huge systems, data does not fit on a single machine. In such cases, sharding refers to splitting the very large database into smaller, faster and more manageable parts called data shards.
- Logical partitioning of server.
- example - column countryName used for sharding will make unequal size of partition after sharding.
- partition here can be of big size hence use pf kafka is popular.
- RDB can solve big data problem if join can be removed but normalization will go away hence not feasible.
Why can’t we use Sharding for big data problems
- Sharding is Logical partitioning to server to make small
- example - column country used for sharding, this makes unequal size of partitions after sharding.
- partition here can be of big size hence use of kafka is popular.
- Relational DB can solve big data problem if join can be removed but normalization will be compromised hence not feasible option.
- Here, we shard data based on country then, high population density countries will put more load on server for the same operation being performed on other partition.
- SQL Query - Chain of SQL operations (bottom-up approach), uses DAG(Directed Acyclic Graph)
- Kafka - provides on demand scale up/ scale down.
- index scan (kafka) => table scan (RDBMS)
Tools
- Stream Processor
- Batch Processor
- Message Brokers
Buzz Words
- Big Data
- Web-scale
- Sharding
- Cloud services
- MapReduce
- Real-time
- Elastic Search - Unstructured Data Structure
- single-node versus distributed systems
- online/interactive versus offline/batch processing systems
- Real life example of scaling using MySQL
- Paxos Consensus