Introduction to Trie
- Efficient information retrieval Data Structure.
- Storing keys in BST will take M * log N time
- M - max string length,
- N - No. of keys
- Using trie, we can search the tree in O(M) but the penalty is on the storage requirement.
Memory requirement of trie = 26 * k * N
- k = length of key
- N = No. of keys
Trie Operations
Insert
Search
Delete
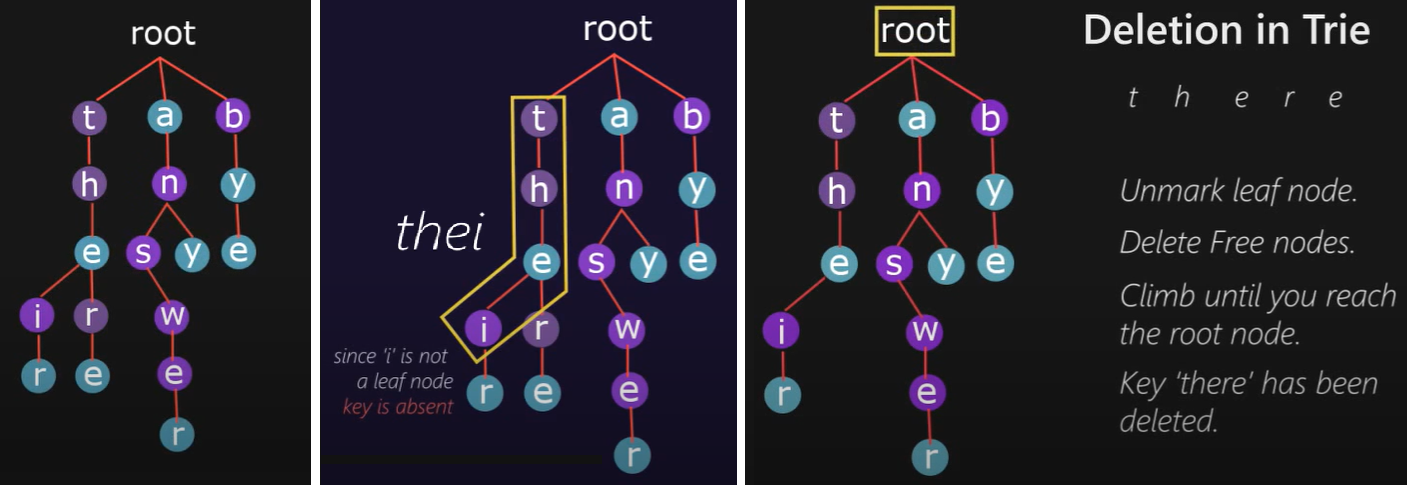
- During delete operation we delete the key in bottom up manner using recursion.
- Deletion should not affect the existing keys in trie.
Steps
- Unmark leaf node.
- delete free nodes.
- climb up till root node.
Trie
- efficient DS for searching words in dictionaries,
- search complexity with Trie is linear in terms of word (or key) length to be searched.
- If we store keys in binary search tree, a well balanced BST will need time proportional to M * log N, M is maximum string length and N is number of keys in tree.
- Using trie, we can search the key in O(M) time. So it is much faster than BST.
- Hashing also provides word search in O(n) time on average. But Trie has no collisions so worst case time complexity is O(n).
- Prefix Search - With Trie, find all words beginning with a prefix (not possible with Hashing).
- Problem with Tries - they require a lot of extra space.
- also known as radix tree or prefix tree.
The Trie structure can be defined as follows :
struct trie_node{
int value; /* Used to mark leaf nodes */
trie_node_t *children[ALPHABET_SIZE];
};
The leaf nodes are in blue.

| Complexity | |
|---|---|
| Insert time | O(M), M is the length of the string. |
| Search time | O(M) |
| Deletion time | O(M) |
| Space | O(ALPHABET_SIZE * M * N) |
N is number of keys in trie, ALPHABET_SIZE is 26 if we are only considering upper case Latin characters.
Trie Examples
- for dictionaries prefix search capability, approximate matching algorithms, including those used in spell checking.
- It is also used for searching Contact from Mobile Contact list OR Phone Directory.