- Introduction
- Architecture
- Setup
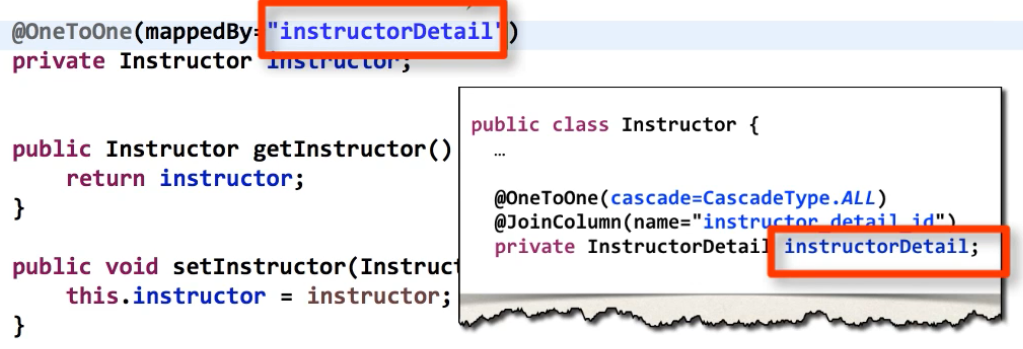
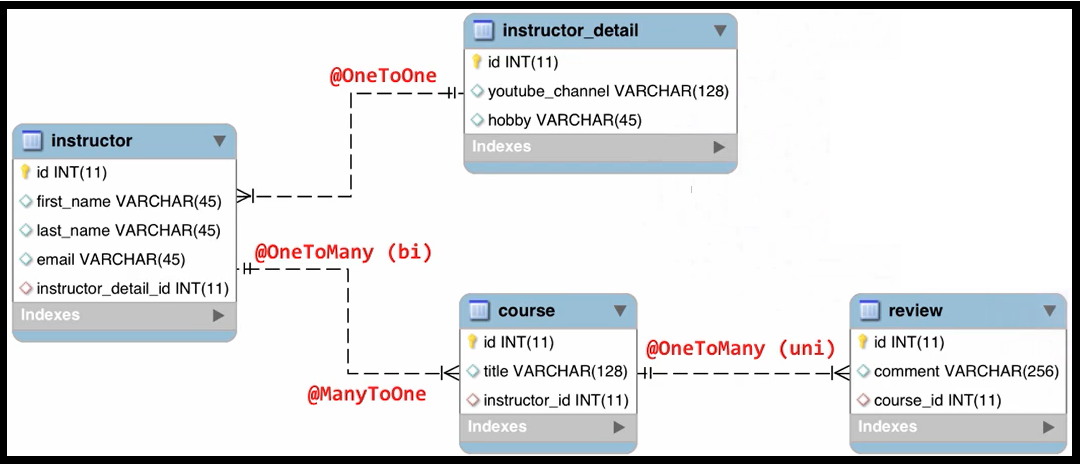
- Associations
- JPA 2 Annotations
- @Entity
- @Id and @GeneratedValue - Primary Keys
- @TableGenerator
- @Id, @IdClass, or @EmbeddedId (Compound Primary Keys)
- @Table and @SecondaryTable
- @Basic
- @Transient
- @Column
- @Temporal
- @ElementCollection
- @Lob
- @MappedSuperclass
- @OrderColumn
- @NamedQuery and @NamedQueries
- @NamedNativeQuery and @NamedNativeQueries
- @Immutable
- @NaturalId
- Modeling Entity Relationships/Associations
- JPA Cascading
- Mapping Inheritance Hierarchies
- SessionFactory and Session
- Lazy Loading
- Entity / Persistence LifeCycle States
- Hibernate Collections
- Hibernate Queries
- Hibernate HQL
- Criteria Queries
- Hibernate Cache
- Hibernate Transaction Management
- Hibernate C3P0 Connection Pool
- Hibernate Validations
- Hibernate - Misc
- n+1 select problem
- Store Procedure Call
Introduction
HIbernate is ORM tool, Domain model persistence for relational databases.
What is JDBC?
- Java Database Connectivity
- provides a set of Java-API for accessing the Relational databases from Java program.
- JDBC provides a flexible architecture to write a database independent application that can run on different platforms and interact with different DBMS without any modification.
Persistence
- application’s data to outlive the applications process.
- Hibernate ORM is concerned with data persistence as it applies to relational databases (RDBMS).
| Pros of JDBC | Cons of JDBC |
|---|---|
| Clean and simple SQL processing | Complex if it is used in large projects |
| Good performance with large data | Large programming overhead |
| Very good for small applications | No encapsulation |
| Simple syntax so easy to learn | Hard to implement MVC concept |
| Query is DBMS specific |
ORM (Object Relational Mapping)
- Object-Relational Mapping (ORM)
- Programming technique for converting data between relational DB and OOP languages such as Java, C# etc.
- Used in Data Layer of application
- Implements JPA
JPA implementation follows the rules set by JPA specifications so that if in future, we want to use some other provider (Not Hibernate) which implements JPA, we can do it with minimal changes.
An ORM solution consists of the following four entities:
- An API to perform basic CRUD operations on objects of persistent classes.
- A language or API to specify queries that refers to classes and properties of classes.
- A configurable facility for specifying mapping metadata.
- A technique to interact with transactional objects to perform dirty checking, lazy association fetching, and other optimization functions.
Why ORM?

‘Object-Relational Impedance Mismatch’ (sometimes called the ‘Paradigm Mismatch’) is just a fancy way of saying that object models and relational models do not work very well together.
Other ORM - Enterprise JavaBeans Entity Beans, Java Data Objects, Castor, TopLink, Spring DAO, Hibernate etc.
Consider below objects need to be stored and retrieved into the following RDBMS table:
- 1st problem, what if we need to modify the design of our database after having developed few pages or our application?
- 2nd problem, Loading and storing objects in a relational database exposes us to the following five mismatch problems.
public class Employee {
private int id;
private String first_name;
private String last_name;
private int salary;
public Employee() {}
// getter-setters
}
create table EMPLOYEE (
id INT NOT NULL auto_increment,
first_name VARCHAR(20) default NULL,
last_name VARCHAR(20) default NULL,
salary INT default NULL,
PRIMARY KEY (id)
);
RDBMS represent data in a tabular format, whereas object-oriented languages, such as Java, represent it as an interconnected graph of objects. Loading and storing graphs of objects using a tabular relational database exposes us to 5 mismatch problems.
Problems ORM Solves
1. Granularity
- Sometimes you will have an object model which has more classes than the number of corresponding tables in the database (Object model is more granular than the relational model). Take for example the notion of an Address.
- The greater the granularity, the deeper the level of detail. Granularity is usually used to characterize the scale or level of detail in a set of data.
2. Subtypes (inheritance)
Inheritance is a natural paradigm in object-oriented programming languages. However, RDBMSs do not define anything similar.
3. Identity
A RDBMS defines exactly one notion of ‘sameness’: the primary key. Java, however, defines both object identity a==b and object equality a.equals(b).
4. Associations
- OOP associations - using references
- RDBMS associations - foreign key column.
- If you need bidirectional relationships in Java, you must define the association twice. Likewise, you cannot determine the multiplicity of a relationship by looking at the object domain model.
5. Data navigation
- The way you access data in Java is fundamentally different than the way you do it in a relational database.
- In Java, you navigate from one association to another walking the object network. This is not an efficient way of retrieving data from a relational database. You typically want to minimize the number of SQL queries and thus load several entities via JOINs and select the targeted entities before you start walking the object network.
Hibernate vs JDBC
JDBC
- DB specific
- need to know SQL
- query tuning is to be done by the database authors.
- java cache is to be implemented
- Developer writes code for mapping Object to DB schema
- only native Structured Query Language (SQL)
- all exceptions are checked exceptions, we must write code in try, catch and throws
- will rises an error like “View not exist”
Hibernate
- code will work well for all databases (Oracle, MySQL etc)
- wrapper over JDBC API or some other api. (Dialects)
- It provided Dialect classes, so we no need to write sql queries in hibernate, instead we use the methods provided by that API.
- No knowledge of SQL is needed as table is treated as an object
- Query tuning is not required in Hibernate, automatic in hibernate by using criteria queries.
- support for cache of hibernate for better performance.
- improves performance during multiple writes for the same data.
- itself takes care of this mapping using mapping files so developer does not need to write code for this.
- provides Hibernate Query Language (HQL) which is similar to SQL syntax and supports polymorphic queries too. It is DB independent
- supports Inheritance, Associations, Collections
- if we save the derived class object, then its base class object will also be stored into the database, it means hibernate supporting inheritance.
- supports relationships like One-To-Many,One-To-One, Many-To-Many-to-Many, Many-To-One
- supports collections like List,Set,Map (Only new collections)
- we only have Un-checked exceptions, so no need to write try, catch, or no need to write throws. Actually in hibernate we have the translator which converts checked to Un-checked.
- has capability to generate primary keys automatically while we are storing the records into database
- if any table not found in the database, it will create the table for us.
- supports annotations, apart from XML.
- Getting pagination in hibernate is quite simple
- Handling DataTypes Boolean <–> Y_N. @Type(type=”Yes_No”)
Advantages
- Lets business code access objects rather than DB tables.
- Hides details of SQL queries from OO logic.
- Based on JDBC ‘under the hood’
- No need to deal with the database implementation.
- Entities based on business concepts rather than database structure.
- Transaction management and automatic key generation.
- Fast development of application.
What are the advantages of Hibernate over JDBC? Some of the important advantages of Hibernate framework over JDBC are:
- Hibernate removes a lot of boiler-plate code that comes with JDBC API, the code looks more cleaner and readable.
- Hibernate supports inheritance, associations and collections. These features are not present with JDBC API.
- Hibernate implicitly provides transaction management, in fact most of the queries can’t be executed outside transaction. In JDBC API, we need to write code for transaction management using commit and rollback. Read more at JDBC Transaction Management.
- JDBC API throws SQLException that is a checked exception, so we need to write a lot of try-catch block code. Most of the times it’s redundant in every JDBC call and used for transaction management. Hibernate wraps JDBC exceptions and throw JDBCException or HibernateException un-checked exception, so we don’t need to write code to handle it. Hibernate built-in transaction management removes the usage of try-catch blocks.
- Hibernate Query Language (HQL) is more object oriented and close to java programming language. For JDBC, we need to write native sql queries.
- Hibernate supports caching that is better for performance, JDBC queries are not cached hence performance is low.
- Hibernate provide option through which we can create database tables too, for JDBC tables must exist in the database.
- Hibernate configuration helps us in using JDBC like connection as well as JNDI DataSource for connection pool. This is very important feature in enterprise application and completely missing in JDBC API.
- Hibernate supports JPA annotations, so code is independent of implementation and easily replaceable with other ORM tools. JDBC code is very tightly coupled with the application.
Performance
The problem is the startup performance. When hibernate loads, it analyzes all entities and does a lot of pre-caching - it can take about 5-10-15 seconds for a not very big application. So, your 1 second unit test is going to take 11 secods now. Not fun.
In-memory Session
For every transaction, hibernate will store an object in memory for every database row it “touches”. For lots of objects, it can seriously affect performance, unless you explicitly and carefully clean up the in-memory session on your own.
Cascades
Cascades allow you to simplify working with object graphs. Example, if you save root object, you can configure hibernate to save children as well. The problem starts when your object graph grows complex.
Lazy Loading
Lazy Loading means that every time you load an object, hibernate will not load all it’s related objects but instead will provide place holders which will be resolved as soon as you try to access them. This behaviour otherwise you will get cryptic errors, “LazyInitializationException”. Depending on the order of how you load your objects and your object graph you may hit “n+1 selects problem”.
Schema Upgrades
Hibernate allows easy schema changes by just refactoring java code and restarting. It’s great when you start. But then you release version one. And unless you want to lose your customers you need to provide them schema upgrade scripts. Which means no more simple refactoring as all schema changes must be done in SQL.
Views and Stored Procedures
Hibernate requires exclusive write access to the data it works with. Which means you can’t really use views, stored procedures and triggers as those can cause changes to data with hibernate not aware of them. You can have some external processes writing data to the database in a separate transaction. But if you do, your cache will have invalid data. This is one more thing to care about.
Single Threaded Sessions
Hibernate sessions are single threaded. Any object loaded through a session can only be accessed (including reading) from the same thread. This is acceptable for server-side applications but might complicate things unnecessary if you are doing GUI based application.
What is Java Persistence API (JPA)?
Java Persistence API (JPA) provides specification for managing the relational data in applications. JPA specification is defined with annotations in javax.persistence package. Using JPA annotation helps us in writing implementation independent code.
Saving Without Hibernate
- JDBC DB Configuration – ip, port, user, password
- Write Model Object
- Service method to create model object
- DB Design - Table and mappings
- DAO method to save using SQL query.
Saving with Hibernate
- JDBC DB config – hibernate config
- Model Object – Annotations
- Service method to create model object – use hibernate api rather than jdbc save,
- DB Design -not needed 😊
- DAO method to save the object using SQL query - Not needed (All boilerplate mapping stuff)
Architecture
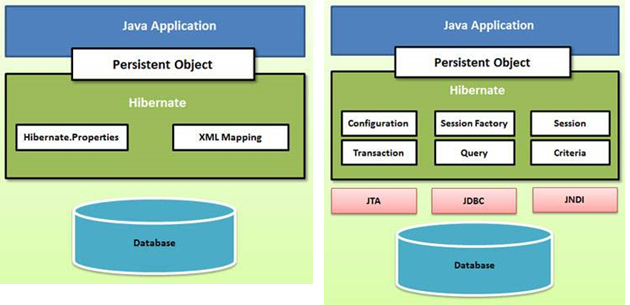
Name some important interfaces of Hibernate framework?
-
SessionFactory (org.hibernate.SessionFactory) SessionFactory is an immutable thread-safe cache of compiled mappings for a single database. We need to initialize SessionFactory once and then we can cache and reuse it. SessionFactory instance is used to get the Session objects for database operations.
-
Session (org.hibernate.Session) Session is a single-threaded, short-lived object representing a conversation between the application and the persistent store. It wraps JDBC java.sql.Connection and works as a factory for org.hibernate.Transaction. We should open session only when it’s required and close it as soon as we are done using it. Session object is the interface between java application code and hibernate framework and provide methods for CRUD operations.
-
Transaction (org.hibernate.Transaction) Transaction is a single-threaded, short-lived object used by the application to specify atomic units of work. It abstracts the application from the underlying JDBC or JTA transaction. A org.hibernate.Session might span multiple org.hibernate.Transaction in some cases.
Hibernate Interfaces
Setup
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
This dependency includes JPA API, JPA Implementation, JDBC and other needed libraries. Since the default JPA implementation is Hibernate, this dependency is actually enough to bring it in as well.
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>3.0.0.ga</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-annotations</artifactId>
<version>3.3.0.ga</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
XML Based
Configuration File
What is hibernate configuration file?
- Hibernate configuration file contains database specific configurations and used to initialize SessionFactory.
- We provide database credentials or JNDI resource information in the hibernate configuration xml file.
- Some other important parts of hibernate configuration file is Dialect information, so that hibernate knows the database type and mapping file or class details.
<!-- hibernate.cfg.xml -->
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 5.3//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-5.3.dtd">
<hibernate-configuration>
<session-factory>
<property name="connection.driver_class">oracle.jdbc.driver.OracleDriver</property>
<property name="connection.url">jdbc:oracle:thin:@localhost:1521:xe</property>
<property name="connection.username">system</property>
<property name="connection.password">jtp</property>
<property name="connection.pool_size">10</property>
<property name="hibernate.c3p0.min_size">10</property>
<property name="dialect">org.hibernate.dialect.Oracle9Dialect</property>
<property name="show_sql">true</property>
<property name="hbm2ddl.auto">create</property>
<property name="cache.provider_class">org.hibernate.cache.NoCacheProvider</property>
<mapping resource="employee.hbm.xml"/>
</session-factory>
</hibernate-configuration>
Mapping File
What is hibernate mapping file?
Hibernate mapping file is used to define the entity bean fields and database table column mappings. We know that JPA annotations can be used for mapping but sometimes XML mapping file comes handy when we are using third party classes and we can’t use annotations.
<!-- employee.hbm.xml -->
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 5.3//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-5.3.dtd">
<hibernate-mapping>
<class name="com.javatpoint.mypackage.Employee" table="emp1000">
<id name="id">
<generator class="assigned"></generator>
</id>
<property name="firstName"></property>
<property name="lastName"></property>
</class>
</hibernate-mapping>
StandardServiceRegistry ssr = new StandardServiceRegistryBuilder().configure("hibernate.cfg.xml").build();
Metadata meta = new MetadataSources(ssr).getMetadataBuilder().build();
SessionFactory factory = meta.getSessionFactoryBuilder().build();
Session session = factory.openSession();
Transaction t = session.beginTransaction();
Employee e1=new Employee();
e1.setId(101);
e1.setFirstName("Gaurav");
e1.setLastName("Chawla");
session.save(e1);
t.commit();
factory.close();
session.close();
Properties and Annotation
Hibernate Properties
# Hibernate Properties
spring.datasource.url = jdbc:mysql://localhost:3306/netgloo_blog?useSSL=false
# Username and password
spring.datasource.username = root
spring.datasource.password = root
# Keep the connection alive if idle for a long time (needed in production)
spring.datasource.testWhileIdle = true
spring.datasource.validationQuery = SELECT 1
# Use spring.jpa.properties.* for Hibernate native properties (the prefix is stripped before adding them to the entity manager).
# Show or not log for each sql query
spring.jpa.show-sql = true
# Hibernate ddl auto (create, create-drop, update): with "update" the database
# schema will be automatically updated accordingly to java entities found in the project
spring.jpa.hibernate.ddl-auto = update
# Naming strategy
spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.ImprovedNamingStrategy
# Allows Hibernate to generate SQL optimized for a particular DBMS
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
Hibernate Mapping
we can face situations where two entities can be related and must be referenced from each other, in either uni-direction or in bi-direction.
A common mistake by beginners, when designing entity models, is to try to make all associations bidirectional. Remember that associations that are not a natural part of the object model should not be forced into it. Hibernate Query Language (HQL) often proves a more natural way to access the required information when needed.
Ideally, we would like to dictate that only changes to one end of the relationship will result in any updates to the foreign key; and indeed, Hibernate allows us to do this by marking one end of the association as being managed by the other.
In hibernate mapping associations, one (and only one) of the participating classes is referred to as “managing the relationship” and other one is called “managed by” using ‘mappedBy’ property. We should not make both ends of association “managing the relationship”. Never do it.
Note that “mappedBy” is purely about how the foreign key relationships between entities are saved. It has nothing to do with saving the entities themselves using cascade functionality.
While Hibernate lets us specify that changes to one association will result in changes to the database, it does not allow us to cause changes to one end of the association to be automatically reflected in the other end in the Java POJOs. We must use cascading capabilities for doing so.
Hibernate mapping Annotations
Hibernate supports JPA annotations and it has some other annotations in org.hibernate.annotations package. Some of the important JPA and hibernate annotations used are:
| javax.persistence.Entity | Used with model classes to specify that they are entity beans. |
| javax.persistence.Table | Used with entity beans to define the corresponding table name in database. |
| javax.persistence.Access | Used to define the access type, either field or property. Default value is field and if you want hibernate to use getter/setter methods then you need to set it to property. |
| javax.persistence.Id | Used to define the primary key in the entity bean. |
| javax.persistence.EmbeddedId | Used to define composite primary key in the entity bean. |
| javax.persistence.Column | Used to define the column name in database table. |
| javax.persistence.GeneratedValue | Used to define the strategy to be used for generation of primary key. Used in conjunction with javax.persistence.GenerationType enum. |
| javax.persistence.OneToOne | Used to define the one-to-one mapping between two entity beans. We have other similar annotations as OneToMany, ManyToOne and ManyToMany |
| javax.persistence.PrimaryKeyJoinColumn | Used to define the property for foreign key. Used with org.hibernate.annotations .GenericGenerator and org.hibernate.annotations.Parameter |
| org.hibernate.annotations.Cascade | Used to define the cascading between two entity beans, used with mappings. It works in conjunction with org.hibernate.annotations.CascadeType |
Here are two classes showing usage of these annotations.
@Entity
@Table(name = "EMPLOYEE")
/**@Table(name = "EMPLOYEE", uniqueConstraints = {
@UniqueConstraint(columnNames = "ID"),
@UniqueConstraint(columnNames = "EMAIL") })*/
@Access(value=AccessType.FIELD)
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "emp_id")
private long id;
@Column(name = "emp_name")
/**@Column(name = "emp_name", unique = false, nullable = false, length = 100)*/
private String name;
@OneToOne(mappedBy = "employee")
@Cascade(value = org.hibernate.annotations.CascadeType.ALL)
private Address address;
//getter setter methods
}
@Entity
@Table(name = "ADDRESS")
@Access(value = AccessType.FIELD)
public class Address {
@Id
@Column(name = "emp_id", unique = true, nullable = false)
@GeneratedValue(generator = "gen")
@GenericGenerator(name = "gen", strategy = "foreign", parameters = {
@Parameter(name = "property", value = "employee")
})
private long id;
@Column(name = "address_line1")
private String addressLine1;
@OneToOne
@PrimaryKeyJoinColumn
private Employee employee;
//getter setter methods
}
Associations
Two simple entities (AccountEntity and EmployeeEntity) for this example and then create one-to-one association.
@Entity
@Table(name = "Account")
public class AccountEntity implements Serializable{
private static final long serialVersionUID = 1L;
@Id
@Column(name = "ID", unique = true, nullable = false)
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Integer accountId;
@Column(name = "ACC_NO", unique = false, nullable = false, length = 100)
private String accountNumber;
//We will define the association here
EmployeeEntity employee;
//Getters and Setters are not shown for brevity
}
@Entity
@Table(name = "Employee")
public class EmployeeEntity implements Serializable{
private static final long serialVersionUID = -1798070786993154676L;
@Id
@Column(name = "ID", unique = true, nullable = false)
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Integer employeeId;
@Column(name = "FIRST_NAME", unique = false, nullable = false, length = 100)
private String firstName;
@Column(name = "LAST_NAME", unique = false, nullable = false, length = 100)
private String lastName;
//We will define the association here
AccountEntity account;
//Getters and Setters are not shown for brevity
}
Managed by both entities
//Inside EmployeeEntity.java
@OneToOne
AccountEntity account;
//Inside AccountEntity.java
@OneToOne
EmployeeEntity employee;
//acc.setEmployee(emp);
sessionOne.save(emp);
EmployeeEntity employee = (EmployeeEntity) sessionTwo.get(EmployeeEntity.class, genEmpId);
account.getEmployee().getEmployeeId()
// throws null pointer exception
With above association, both ends are managing the association so both must be updated with information of each other using setter methods defined in entity java files. If you fail to do so, you will not be able to fetch the associated entity information and it will be returned as null.
Console Log output
FIRST_NA2_1_0_,
employeeen0_.LAST_NAME as LAST_NAM3_1_0_, accountent1_.ID as ID1_0_1_, accountent1_.ACC_NO as ACC_NO2_0_1_,
accountent1_.employee_ID as employee3_0_1_, employeeen2_.ID as ID1_1_2_, employeeen2_.account_ID as
account_4_1_2_,
employeeen2_.FIRST_NAME as FIRST_NA2_1_2_, employeeen2_.LAST_NAME as LAST_NAM3_1_2_ from Employee
employeeen0_ left outer join Account accountent1_ on employeeen0_.account_ID=accountent1_.ID
left outer join Employee employeeen2_ on accountent1_.employee_ID=employeeen2_.ID where employeeen0_.ID=?
Both tables have foreign key association with column names employee_ID and account_ID respectively. It’s example of circular dependency in data and can easily bring down your application any time.
To correctly store above relationship, you must un-comment the line “acc.setEmployee(emp);”. After uncommenting the line, you will be able to store and retrieve the association as desired but still there is circular dependency.
Managed by single entity
//Inside EmployeeEntity.java
@OneToOne
AccountEntity account;
//Inside AccountEntity.java
@OneToOne (mappedBy = "account")
EmployeeEntity employee;
Now to tell hibernate the association is managed by EmployeeEntity, we will add ‘mappedBy‘ attribute inside AccountEntity to make it manageable. Now to test above code we will have to set the association only once using “emp.setAccount(acc);” and employee entity is which is managing the relationship. AccountEntity does not need to know anything explicitly.
emp.setAccount(acc);
//acc.setEmployee(emp);
sessionOne.save(acc);
account.getEmployee().getEmployeeId()
You see that you do not need to tell anything to account entity (‘acc.setEmployee(emp)‘ is commented). Employee entity is managing the association both ways.
Another observation is regarding foreign key columns which we have only one now i.e. account_ID is Employee table. So no circular dependency as well. All good.
Associations for Various Mappings
Above example shows how to manage association between entities in one-to-one mapping. In above example, we could have chosen the association managed by AccountEntity as well and things would have worked out pretty well with minor code changes. But in case of other mappings (e.g. One-to-many or Many-to-one), you will not have the liberty to define associations at your will. You need rules.
Below table shows how you can select the side of the relationship that should be made the owner of a bi-directional association. Remember that to make an association the owner, you must mark the other end as being mapped by the other.
| TYPE OF ASSOCIATION | OPTIONS/ USAGE |
|---|---|
| One-to-one | Either end can be made the owner, but one (and only one) of them should be; if you don’t specify this, you will end up with a circular dependency. |
| One-to-many | The many end must be made the owner of the association. |
| Many-to-one | This is the same as the one-to-many relationship viewed from the opposite perspective, so the same rule applies: the many end must be made the owner of the association. |
| Many-to-many | Either end of the association can be made the owner. |
If this all seems rather confusing, just remember that association ownership is concerned exclusively with the management of the foreign keys in the database and that’s it.
JPA 2 Annotations
Annotation
- Needs access of source code to modify mapping.
import javax.persistence.* ;
@Entity
public class Sample {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
public Integer id;
public String name;
}
Mapping
- Useful when source code is not available
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-mapping
PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping default-access="field">
<class name="Sample">
<id type="int" column="id">
<generator class="native"/>
</id>
<property name="name" type="string"/>
</class>
</hibernate-mapping>
@Entity
It marks this class as an entity bean, so it must have a no-argument constructor that is visible.
@Entity
public class EmployeeEntity implements Serializable{
public EmployeeEntity(){ }
//Other code
}
@Id and @GeneratedValue - Primary Keys
- Natural Key – email ID for business logic, Needs to provided with a value
- Surrogate Key – Primary Key (No business significance), serial number column. Hibernate can generate.
@Id
private Integer employeeId;
@Id
public Integer getEmployeeId(){ return employeeId; }
Property access means that Hibernate will call the mutator/setter instead of actually setting the field directly, what it does in case of field access. This gives flexibility to alter the value of actual value set in id field if needed. Additionally, you can apply extra logic on setting of ‘id’ field in mutator for other fields as well.
@Id
@GeneratedValue (strategy = GenerationType.SEQUENCE)
private Integer employeeId;
//OR a more complex use can be
@Id
@GeneratedValue(strategy=GenerationType.TABLE ,generator="employee_generator")
@TableGenerator(name="employee_generator",
table="pk_table",
pkColumnName="name",
valueColumnName="value",
allocationSize=100)
private Integer employeeId;
the default GenerationType is AUTO.
There are four different types of primary key generators on GeneratorType, as follows:
- AUTO: Hibernate decides which generator type to use, based on the database’s support for primary key generation.
- IDENTITY: The database is responsible for determining and assigning the next primary key.
- SEQUENCE: Some databases support a SEQUENCE column type. It uses @SequenceGenerator.
- TABLE: This type keeps a separate table with the primary key values. It uses @TableGenerator.
The generator attribute allows the use of a custom generation mechanism shown in above code example.
@Id
@GeneratedValue(strategy=SEQUENCE,generator="seq1")
@SequenceGenerator(name="seq1",sequenceName="HIB_SEQ")
private Integer employeeId;
Use strategy as IDENTITY for some some DB, SEQUENCE for some other DB.
@TableGenerator
annotation is used in a very similar way to the @SequenceGenerator annotation, but because @TableGeneratormanipulates a standard database table to obtain its primary key values, instead of using a vendor-specific sequence object, it is guaranteed to be portable between database platforms.
For optimal portability and optimal performance, you should not specify the use of a table generator, but instead use the @GeneratorValue(strategy=GeneratorType.AUTO) configuration, which allows the persistence provider to select the most appropriate strategy for the database in use.
optional attributes are as follows:
- allocationSize: Allows the number of primary keys set aside at one time to be tuned for performance.
- catalog: Allows the catalog that the table resides within to be specified.
- initialValue: Allows the starting primary key value to be specified.
- pkColumnName: Allows the primary key column of the table to be identified. The table can contain the details necessary for generating primary key values for multiple entities.
- pkColumnValue: Allows the primary key for the row containing the primary key generation information to be identified.
- schema: Allows the schema that the table resides within to be specified.
- table: The name of the table containing the primary key values.
- uniqueConstraints: Allows additional constraints to be applied to the table for schema generation.
- valueColumnName: Allows the column containing the primary key generation information for the current entity to be identified.
@Id, @IdClass, or @EmbeddedId (Compound Primary Keys)
For multi-column primary key, You must create a class to represent this primary key. It will not require a primary key of its own, of course, but it must be a public class, must have a default constructor, must be serializable, and must implement hashCode() and equals() methods to allow the Hibernate code to test for primary key collisions.
Your three strategies for using this primary key class once it has been created are as follows:
- Mark it as @Embeddable and add to your entity class a normal property for it, marked with @Id.
- Add to your entity class a normal property for it, marked with @EmbeddableId.
- Add properties to your entity class for all of its fields, mark them with @Id, and mark your entity class with @IdClass, supplying the class of your primary key class.
The use of @Id with a class marked as @Embeddable is the most natural approach. The @Embeddable tag can be used for non-primary key embeddable values anyway. It allows you to treat the compound primary key as a single property, and it permits the reuse of the @Embeddable class in other tables.
One thing worth pointing out: the embedded primary key classes must be serializable.
// Example 1:
@Embeddable
public class EmploymentPeriod {
@Temporal(DATE)
java.util.Date startDate;
@Temporal(DATE)
java.util.Date endDate;
...
}
Example 2:
// @Embeddable – Tells hibernate not to create a table for the class.
@Embeddable
public class PhoneNumber {
protected String areaCode;
protected String localNumber;
@ManyToOne PhoneServiceProvider provider;
...
}
@Entity
public class PhoneServiceProvider {
@Id protected String name;
...
}
// Example 3:
@Embeddable
public class Address {
protected String street;
protected String city;
protected String state;
@Embedded
protected Zipcode zipcode;
}
@Embeddable
public class Zipcode {
protected String zip;
protected String plusFour;
}
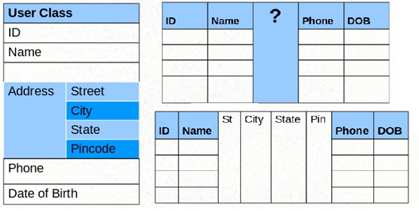
In this case @Embeddable and @Embedded will work. But what if we have Home Address and Office Address? @Embedded will be there but field names will conflict, hence override its attribute.
@Embedded
@AttributeOverrides({
@AttributeOverride(name="street",
column=@Column(name="Office_Street")),
@AttributeOverride(name="city",
column=@Column(name="Office_City"))
})
private Address homeAddress;
- Entity – Data + Needs to be saved independently ie. Has a meaning of its own
- Value Object – Data + Needs to be saved, but doesn’t have a meaning of itself(dependent). Example – Address (who’s address)
@Table and @SecondaryTable
By default, table names are derived from the entity names. Therefore, given a class Employee with a simple @Entity annotation, the table name would be “employee”, adjusted for the database’s configuration. If the entity name is changed (by providing a different name in the @Entity annotation, such as @Entity(“EMP_MASTER”)), the new name will be used for the table name.
@Table annotation provides four attributes, allowing you to override the name of the table, its catalog, and its schema, and to enforce unique constraints on columns in the table.
@SecondaryTable annotation provides a way to model an entity bean that is persisted across several different database tables.
your entity bean can have an @SecondaryTableannotation, or an @SecondaryTables annotation in turn containing zero or more @SecondaryTable annotations.
@SecondaryTable annotation takes the same basic attributes as the @Table annotation, with the addition of the join attribute. The join attribute defines the join column for the primary database table. It accepts an array of javax.persistence.PrimaryKeyJoinColumn objects. If you omit the join attribute, then it will be assumed that the tables are joined on identically named primary key columns.
@Entity
@Table(name = "employee")
@SecondaryTable(name = "employee_details")
public class EmployeeEntity implements Serializable {
@Id
@GeneratedValue (strategy = GenerationType.SEQUENCE)
private Integer employeeId;
private String firstName;
private String lastName;
@Column(table = "employee_details")
public String address;
}
@Entity
@Table(
name="employee",
uniqueConstraints={@UniqueConstraint(columnNames="firstName")}
)
@SecondaryTable(name = "employee_details")
public class EmployeeEntity implements Serializable{}
Columns in the primary or secondary tables can be marked as having unique values within their tables by adding one or more appropriate @UniqueConstraint annotations to @Table or @SecondaryTable’s uniqueConstraints attribute. Alternatively, You may also set uniqueness at the field level with the unique attribute on the @Column attribute.
@Basic
By default, properties and instance variables in your POJO are persistent; Hibernate will store their values for you. The simplest mappings are therefore for the “basic” types. These include primitives, primitive wrappers, arrays of primitives or wrappers, enumerations, and any types that implement Serializable but are not themselves mapped entities.
These are all mapped implicitly—no annotation is needed. By default, such fields are mapped to a single column, and eager fetching is used to retrieve them. Also, when the field or property is not a primitive, it can be stored and retrieved as a null value. This default behavior can be overridden by applying the @Basic annotation to the appropriate class member
@Basic (fetch = FetchType.LAZY, optional = false) // false means associated column should be created NOT NULL
private String firstName;
@Transient
Some fields, such as calculated values, may be used at run time only, and they should be discarded from objects as they are persisted into the database. The JPA specification provides the @Transient annotation for these transient fields.
@Transient
private Integer age;
Static or transient – doesn’t save to DB
@Column
used to specify the details of the column to which a field or property will be mapped.
attributes commonly being overridden:
- name : permits the name of the column to be explicitly specified—by default, this would be the name of the property.
- length : permits the size of the column used to map a value (particularly a String value) to be explicitly defined. The column size defaults to 255, which might otherwise result in truncated String data, for example.
- nullable : permits the column to be marked NOT NULL when the schema is generated. The default is that fields should be permitted to be null; however, it is common to override this when a field is, or ought to be, mandatory.
- unique : permits the column to be marked as containing only unique values. This defaults to false, but commonly would be set for a value that might not be a primary key but would still cause problems if duplicated (such as username).
@Column(name="FNAME",length=100,nullable=false)
private String firstName;
@Temporal(TemporalType.TIME)
java.util.Date startingTime;
@Temporal
java.util.Date or java.util.Calendar types represent temporal data. By default, these will be stored in a column with the TIMESTAMP data type, but this default behavior can be overridden with the @Temporalannotation.
TemporalType enum - DATE, TIME, and TIMESTAMP
@ElementCollection
@ElementCollection annotation for mapping collections of basic or embeddable classes.
@ElementCollection
List<String> passwordHints;
two attributes on the @ElementCollection annotation: targetClass and fetch. The targetClass attribute tells Hibernate which class is stored in the collection. If you use generics on your collection, you do not need to specify targetClass because Hibernate will infer the correct class. The fetch attribute takes a member of the enumeration, FetchType. This is EAGER by default, but can be set to LAZY to permit loading when the value is accessed.
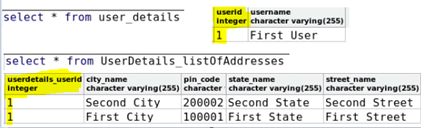
@ElementCollection
@JoinTable(name="USER_ADDRESS", joinColumns={@JoinColumn(name="USER_ID")})
@GenericGenerator(name="hilo-gen", strategy="hilo")
@CollectionId(columns={@Column(name="ADDRESS_ID")}, generator="hilo-gen", type=@Type(type="long"))
private Collection<Address> addresses = new ArrayList<>();
Here USER_ADDRESS has a Foreign Key but no Primary Key hence we use @CollectionId of hibernate specific annotation. To have an indexed order, we have to select a datatype that supports index, ex. ArrayList.
@Lob
String- and character-based types will be stored in an appropriate character-based type i.e. CLOB. All other objects will be stored in a BLOB.
@Lob
String content; // a very long article
@Lob annotation can be used in combination with the @Basic or the @ElementCollection annotation.
@MappedSuperclass
- A special case of inheritance occurs when the root of the hierarchy is not itself a persistent entity, but various classes derived from it are. Such a class can be abstract or concrete. The @MappedSuperclass annotation allows you to take advantage of this circumstance.
- The class marked with @MappedSuperclass is not an entity, and is not query-able (it cannot be passed to methods that expect an entity in the Session or EntityManager objects). It cannot be the target of an association.
- The mapping information for the columns of the superclass will be stored in the same table as the details of the derived class.
@OrderColumn
@OneToMany
@OrderColumn( name="employeeNumber" )
List<Employee> employees;
- Here, we are declaring that an employeeNumber column will maintain a value, starting at 0 and incrementing as each entry is added to the list. The default starting value can be overridden by the base attribute.
- By default, the column can contain null (unordered) values. The nullability can be overridden by setting the nullable attribute to false.
- By default, when the schema is generated from the annotations, the column is assumed to be an integer type; however, this can be overridden by supplying a columnDefinition attribute specifying a different column definition string.
@NamedQuery and @NamedQueries
@NamedQuery and @NamedQueries allow one or more Hibernate Query Language or Java Persistence Query Language (JPQL) queries to be associated with an entity.
@Entity
@NamedQuery(
name="findAuthorsByName",
query="from Author where name = :author"
)
public class Author {
...
}
If a query has no natural association with any of the entity declarations, it is possible to make the @NamedQuery annotation at the package level.
@NamedNativeQuery and @NamedNativeQueries
In general, you should prefer to write HQL queries because then you can let Hibernate handle the intricacies of converting the HQL into the various SQL dialects.
@NamedQueries({
@NamedQuery(name="get-emp-by-name",query="FROM EmployeeBean WHERE fName=:fName")
})
//Equivalent NamedNativeQuery
@NamedNativeQueries(
{
@NamedNativeQuery(
name="get-emp-by-name-native",
query="SELECT * FROM Employees WHERE firstName=:fName",
resultClass=EmployeeEntity.class)
}
)
@Immutable
- Marks an entity as being, well, immutable.
- useful for situations in which your entity represents reference data–things like lists of states, genders, or other rarely mutated data.
Since things like states tend to be rarely changed, someone usually updates the data manually, via SQL or an administration application. Hibernate can cache this data aggressively, which needs to be taken into consideration; if the reference data changes, you’d want to make sure that the applications using it are notified (may use refresh() method) or restarted somehow.
What @Immutable annotation tells Hibernate is that any updates to an immutable entity should not be passed on to the database without giving any error. @Immutable can be placed on a collection too; in this case, changes to the collection (additions, or removals) will cause a HibernateException to be thrown.
@NaturalId
- @Id annotation with @GeneratedValue to create primary keys for records in database. In most real life applications, these primary keys are “artificial primary keys” and referred only inside application runtime. However, there’s also the concept of a “natural ID”, which provides another convenient and logical way to refer to an entity, apart from an artificial or composite primary key.
- An example of natural id might be a Social Security number or a Tax Identification Number in the United States, and PAN number in India. An entity (being a person or a corporation) might have an artificial primary key generated by Hibernate, but it also might have a unique tax identifier. Hibernate allows you to search and load entities based on these natural ids as well. For natural IDs, there are two forms of load mechanisms; one uses the simple natural ID (where the natural ID is one and only one field), and the other uses named attributes as part of a composite natural ID.
@Entity
@Table(name = "Employee")
public class EmployeeEntity implements Serializable{
private static final long serialVersionUID = -1798070786993154676L;
@Id
@Column(name = "ID", unique = true, nullable = false)
private Integer employeeId;
//Natural id can be SSN as well
@NaturalId
Integer SSN;
//Setters and Getters
}
//Load the employee
EmployeeEntity employee1 = (EmployeeEntity) sessionOne.load(EmployeeEntity.class, 1);
//Get the employee for natural id i.e. SSN; This does not execute another SQL SELECT as entity is already present in session
EmployeeEntity employee2 = (EmployeeEntity) sessionOne.bySimpleNaturalId(EmployeeEntity.class).load(12345);
//Verify that employee1 and employee2 refer to same object
assert(employee1 == employee2);
//Get the employee for natural id i.e. SSN; entity is not present in this session
EmployeeEntity employee = (EmployeeEntity) sessionTwo.bySimpleNaturalId(EmployeeEntity.class).load(12345);
Please watch closely that in case of entity already not present in session, and if you get entity using it’s natural id then first primary id is fetched using natural id; and then entity is fetched using this primary id. If entity is already present in session, then reference of same entity is returned without executing additional SELECT statements in database.
Hibernate: select employeeen_.ID as ID1_1_ from Employee employeeen_ where employeeen_.SSN=?
Hibernate: select employeeen0_.ID as ID1_1_0_, employeeen0_.SSN as SSN2_1_0_, employeeen0_.FIRST_NAME as FIRST_NA3_1_0_,
employeeen0_.LAST_NAME as LAST_NAM4_1_0_ from Employee employeeen0_ where employeeen0_.ID=?
How it works
If you look at logs then you will know that when you get an entity by its natural id then
- First primary key of entity is found by executing where clause of natural id
- This primary key is used fetch the information of entity
Composite Natural ID
//Natural id part 1
@NaturalId
Integer seatNumber;
//Natural id part 2
@NaturalId
String departmentName;
//Get the employee for natural id i.e. SSN; entity is not present in this session
EmployeeEntity employee = (EmployeeEntity) sessionOne.byNaturalId(EmployeeEntity.class)
.using("seatNumber", 12345)
.using("departmentName", "IT")
.load();
Entity fetching logic for composite natural id is same as simple natural id. No difference apart from use of multiple natural keys instead one.
Hibernate: insert into Employee (departmentName, FIRST_NAME, LAST_NAME, seatNumber, ID) values (?, ?, ?, ?, ?)
Hibernate: select employeeen_.ID as ID1_1_ from Employee employeeen_ where employeeen_.departmentName=? and employeeen_.seatNumber=?
Hibernate: select employeeen0_.ID as ID1_1_0_, employeeen0_.departmentName as departme2_1_0_, employeeen0_.FIRST_NAME as FIRST_NA3_1_0_,
employeeen0_.LAST_NAME as LAST_NAM4_1_0_, employeeen0_.seatNumber as seatNumb5_1_0_ from Employee employeeen0_ where employeeen0_.ID=?
Modeling Entity Relationships/Associations
How to implement relationships in hibernate?
We can easily implement one-to-one, one-to-many and many-to-many relationships in hibernate. It can be done using JPA annotations as well as XML based configurations. For better understanding, you should go through following tutorials.
- Hibernate One to One Mapping
- Hibernate One to Many Mapping
- Hibernate Many to Many Mapping
@OneToOne
Various supported techniques for one to one mapping
- Using foreign key association
- Using common join table
- Using shared primary key
In hibernate there are 3 ways to create one-to-one relationships between two entities. Either way we have to use @OneToOneannotation.
- First technique is most widely used and uses a foreign key column in one of the tables.
- Second technique uses a rather known solution of having a third table to store mapping between first two tables.
- Third technique is something new which uses a common primary key value in both the tables.
1. Foreign Key
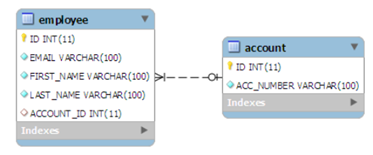
EmployeeEntity.java
@OneToOne
@JoinColumn(name="ACCOUNT_ID")
private AccountEntity account;
AccountEntity.java
@OneToOne(mappedBy="account")
private EmployeeEntity employee;
- @JoinColumn annotation which looks like the @Column annotation. It has one more parameters named referencedColumnName. This parameter declares the column in the targeted entity that will be used to the join.
- If no @JoinColumn is declared on the owner side, the defaults apply. A join column(s) will be created in the owner table and its name will be the concatenation of the name of the relationship in the owner side, _ (underscore), and the name of the primary key column(s) in the owned side.
In a bidirectional relationship, one of the sides (and only one) has to be the owner. The owner is responsible for the association column(s) update. To declare a side as not responsible for the relationship, the attribute mappedBy is used. ‘mappedBy’ refers to the property name of the association on the owner side.
Console
Hibernate: insert into ACCOUNT (ACC_NUMBER) values (?)
Hibernate: insert into Employee (ACCOUNT_ID, EMAIL, FIRST_NAME, LAST_NAME) values (?, ?, ?, ?)
2. with common join table
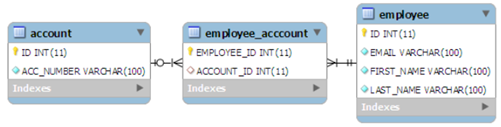
main annotation to be used is @JoinTable. This annotation is used to define the new table name (mandatory) and foreign keys from both of the tables.
@OneToOne(cascade = CascadeType.ALL)
@JoinTable(name="EMPLOYEE_ACCCOUNT", joinColumns = @JoinColumn(name="EMPLOYEE_ID"),
inverseJoinColumns = @JoinColumn(name="ACCOUNT_ID"))
private AccountEntity account;
Console:
Hibernate: insert into ACCOUNT (ACC_NUMBER) values (?)
Hibernate: insert into Employee (EMAIL, FIRST_NAME, LAST_NAME) values (?, ?, ?)
Hibernate: insert into EMPLOYEE_ACCCOUNT (ACCOUNT_ID, EMPLOYEE_ID) values (?, ?)
3. With shared primary key
- In this technique, hibernate will ensure that it will use a common primary key value in both the tables. This way primary key of EmployeeEntity can safely be assumed the primary key of AccountEntity also.
- @PrimaryKeyJoinColumn is the main annotation to be used.
@OneToOne(cascade = CascadeType.ALL)
@PrimaryKeyJoinColumn
private AccountEntity account;
@OneToOne(mappedBy="account", cascade=CascadeType.ALL)
private EmployeeEntity employee;
Console:
Hibernate: insert into ACCOUNT (ACC_NUMBER) values (?)
Hibernate: insert into Employee (ACCOUNT_ID, EMAIL, FIRST_NAME, LAST_NAME) values (?, ?, ?, ?)
@OneToMany
This problem can be solved in two different ways.
- One is to have a foreign key column in account table i.e. EMPLOYEE_ID. This column will refer to primary key of Employee table. This way no two accounts can be associated with multiple employees. Obviously, account number needs to be unique for enforcing this restriction.
- Second approach is to have a common join table lets say EMPLOYEE_ACCOUNT. This table will have two column i.e. EMP_ID which will be foreign key referring to primary key in EMPLOYEE table and similarly ACCOUNT_ID which will be foreign key referring to primary key of ACCOUNT table.
1. With foreign key association
In this approach, both entity will be responsible for making the relationship and maintaining it.
EmployeeEntity should declare that relationship is one to many, and AccountEntity should declare that relationship from its end is many to one.
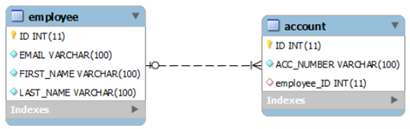
@Entity(name = "ForeignKeyAssoEntity")
@Table(name = "Employee", uniqueConstraints = {
@UniqueConstraint(columnNames = "ID"),
@UniqueConstraint(columnNames = "EMAIL") })
public class EmployeeEntity implements Serializable {
private static final long serialVersionUID = -1798070786993154676L;
@OneToMany(cascade=CascadeType.ALL)
@JoinColumn(name="EMPLOYEE_ID")
private Set<AccountEntity> accounts;
}
@Entity(name = "ForeignKeyAssoAccountEntity")
@Table(name = "ACCOUNT", uniqueConstraints = {@UniqueConstraint(columnNames = "ID")})
public class AccountEntity implements Serializable{
private static final long serialVersionUID = -6790693372846798580L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID", unique = true, nullable = false)
private Integer accountId;
@Column(name = "ACC_NUMBER", unique = true, nullable = false, length = 100)
private String accountNumber;
@ManyToOne
private EmployeeEntity employee;
}
2. with join table
This approach uses a join table to store the associations between account and employee entities. @JoinTable annotation has been used to make this association.
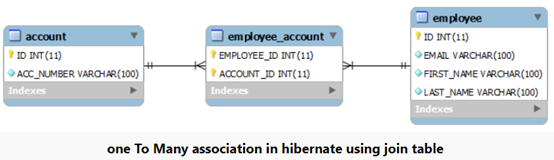
@Entity(name = "JoinTableEmployeeEntity")
@Table(name = "Employee", uniqueConstraints = {
@UniqueConstraint(columnNames = "ID"),
@UniqueConstraint(columnNames = "EMAIL")
})
public class EmployeeEntity implements Serializable {
private static final long serialVersionUID = -1798070786993154676 L;
@OneToMany(cascade = CascadeType.ALL)
@JoinTable(name = "EMPLOYEE_ACCOUNT",
joinColumns = {
@JoinColumn(name = "EMPLOYEE_ID", referencedColumnName = "ID")
},
inverseJoinColumns = {
@JoinColumn(name = "ACCOUNT_ID", referencedColumnName = "ID")
})
private Set < AccountEntity > accounts;
@Entity(name = "JoinTableAccountEntity")
@Table(name = "ACCOUNT", uniqueConstraints = {
@UniqueConstraint(columnNames = "ID")
})
public class AccountEntity implements Serializable {
private static final long serialVersionUID = -6790693372846798580 L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID", unique = true, nullable = false)
private Integer accountId;
@Column(name = "ACC_NUMBER", unique = true, nullable = false, length = 100)
private String accountNumber;
}
}
@ManyToMany
Hibernate many to many mapping is made between two entities where one can have relation with multiple other entity instances. For example, for a subscription service SubscriptionEntity and ReaderEntity can be two type of entities. Any subscription can have multiple readers, where a reader can subscribe to multiple subscriptions.
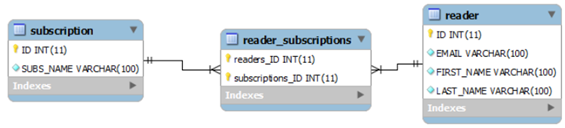
Owner entity is the entity which is responsible make making the association and maintaining it. In our case, I am making ReaderEntity the owner entity. @JoinTable annotation has been used to make this association.
@Entity(name = "ReaderEntity")
@Table(name = "READER", uniqueConstraints = {
@UniqueConstraint(columnNames = "ID"),
@UniqueConstraint(columnNames = "EMAIL")
})
public class ReaderEntity implements Serializable {
private static final long serialVersionUID = -1798070786993154676 L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID", unique = true, nullable = false)
private Integer readerId;
@ManyToMany(cascade = CascadeType.ALL)
@JoinTable(name = "READER_SUBSCRIPTIONS",
joinColumns = {
@JoinColumn(referencedColumnName = "ID")
}, inverseJoinColumns = {
@JoinColumn(referencedColumnName = "ID")
})
private Set < SubscriptionEntity > subscriptions;
}
@Entity(name = "SubscriptionEntity")
@Table(name = "SUBSCRIPTION", uniqueConstraints = {
@UniqueConstraint(columnNames = "ID")
})
public class SubscriptionEntity implements Serializable {
private static final long serialVersionUID = -6790693372846798580 L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID", unique = true, nullable = false)
private Integer subscriptionId;
@ManyToMany(mappedBy = "subscriptions")
private Set < ReaderEntity > readers;
}
JPA Cascading
We learned about mapping associated entities in hibernate already in previous tutorials such as one-to-one mapping and one-to-many mappings. There we wanted to save the mapped entity whenever relationship owner entity got saved. To enable this we had use “CascadeType” attribute.
Take a scenario where an Employee can have multiple Accounts; but one account must be associated with only one employee.
@OneToMany(cascade=CascadeType.ALL, fetch = FetchType.LAZY)
@JoinColumn(name="EMPLOYEE_ID")
private Set<AccountEntity> accounts;
@Entity
@Table(name = "Account")
public class AccountEntity implements Serializable{
private static final long serialVersionUID = 1L;
@Id
@Column(name = "ID", unique = true, nullable = false)
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Integer accountId;
@Column(name = "ACC_NO", unique = false, nullable = false, length = 100)
private String accountNumber;
@OneToOne (mappedBy="accounts", fetch = FetchType.LAZY)
private EmployeeEntity employee;
}
“cascade=CascadeType.ALL” and it essentially means that any change happened on EmployeeEntity must cascade to AccountEntity as well. If you save an employee, then all associated accounts will also be saved into database. If you delete an Employee then all accounts associated with that Employee also be deleted. Simple enough.
But what if we only want to cascade only save operations but not delete operation. Then we need to clearly specify it using below code.
@OneToMany(cascade=CascadeType.PERSIST, fetch = FetchType.LAZY)
@JoinColumn(name="EMPLOYEE_ID")
private Set<AccountEntity> accounts;
Now only when save() or persist() methods are called using employee instance then only accounts will be persisted. If any other method is called on session, it’s effect will not affect/cascade to accounts.
JPA Cascade Types
The cascade types supported by the Java Persistence Architecture are as below:
- CascadeType.PERSIST : cascade type presist means that save() or persist() operations cascade to related entities.
- CascadeType.MERGE : cascade type merge means that related entities are merged when the owning entity is merged.
- CascadeType.REFRESH : cascade type refresh does the same thing for the refresh() operation.
- CascadeType.REMOVE : cascade type remove removes all related entities association with this setting when the owning entity is deleted.
- CascadeType.DETACH : cascade type detach detaches all related entities if a “manual detach” occurs.
- CascadeType.ALL : cascade type all is shorthand for all of the above cascade operations.
There is no default cascade type in JPA. By default no operations are cascaded.

The cascade configuration option accepts an array of CascadeTypes; thus, to include only refreshes and merges in the cascade operation for a One-to-Many relationship as in our example, you might see the following:
@OneToMany(cascade={CascadeType.REFRESH, CascadeType.MERGE}, fetch = FetchType.LAZY)
@JoinColumn(name="EMPLOYEE_ID")
private Set<AccountEntity> accounts;
Above cascading will cause accounts collection to be only merged and refreshed.
Orphan Removal
Apart from JPA provided cascade types, there is one more cascading operation in hibernate which is not part of the normal set above discussed, called “orphan removal”. This removes an owned object from the database when it’s removed from its owning relationship.
In our Employee and Account entity example, I have updated them as below and have mentioned “orphanRemoval = true” on accounts. It essentially means that whenever I will remove an ‘account from accounts set’ (which means I am removing the relationship between that account and Employee); the account entity which is not associated with any other Employee on database (i.e. orphan) should also be deleted.
@Entity
@Table(name = "Employee")
public class EmployeeEntity implements Serializable{
private static final long serialVersionUID = -1798070786993154676L;
@Id
@Column(name = "ID", unique = true, nullable = false)
private Integer employeeId;
@Column(name = "FIRST_NAME", unique = false, nullable = false, length = 100)
private String firstName;
@Column(name = "LAST_NAME", unique = false, nullable = false, length = 100)
private String lastName;
@OneToMany(orphanRemoval = true, mappedBy = "employee")
private Set<AccountEntity> accounts;
}
@Entity (name = "Account")
@Table(name = "Account")
public class AccountEntity implements Serializable{
private static final long serialVersionUID = 1L;
@Id
@Column(name = "ID", unique = true, nullable = false)
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Integer accountId;
@Column(name = "ACC_NO", unique = false, nullable = false, length = 100)
private String accountNumber;
@ManyToOne
private EmployeeEntity employee;
}
Hibernate Cascading
What is cascading and what are different types of cascading?
- When we have relationship between entities, then we need to define how the different operations will affect the other entity. This is done by cascading and there are different types of it.
- Here is a simple example of applying cascading between primary and secondary entities.
import org.hibernate.annotations.Cascade;
@Entity
@Table(name = "EMPLOYEE")
public class Employee {
@OneToOne(mappedBy = "employee")
@Cascade(value = org.hibernate.annotations.CascadeType.ALL)
private Address address;
}
- Hibernate CascadeType enum constants are little bit different from JPA javax.persistence.CascadeType, so we need to use the Hibernate CascadeType and Cascade annotations for mappings, as shown in above example.
- Commonly used cascading types as defined in CascadeType enum are:
- None: No Cascading, it’s not a type but when we don’t define any cascading then no operations in parent affects the child.
- ALL: Cascades save, delete, update, evict, lock, replicate, merge, persist. Basically everything
- SAVE_UPDATE: Cascades save and update, available only in hibernate.
- DELETE: Corresponds to the Hibernate native DELETE action, only in hibernate.
- DETATCH, MERGE, PERSIST, REFRESH and REMOVE – for similar operations
- LOCK: Corresponds to the Hibernate native LOCK action.
- REPLICATE: Corresponds to the Hibernate native REPLICATE action.
org.hibernate.annotations.Cascade
Used to define the cascading between two entity beans, used with mappings. It works in conjunction with org.hibernate.annotations.CascadeType
Mapping Inheritance Hierarchies
Hibernate supports the three basic inheritance mapping strategies:
- table per class hierarchy
- table per subclass
- table per concrete class
In addition, Hibernate supports a fourth, slightly different kind of polymorphism:
- implicit polymorphism
Feature of OOP, no equivalent in Relational Model.
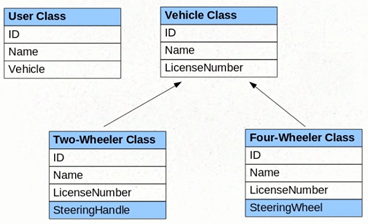
Use hibernate implementation of inheritance of when strong implementation of inheritance is used like polymorphism, dynamic assignment of objects.
InheritanceType.SINGLE_TABLE
InheritanceType.TABLE_PER_CLASS
InheritanceType.JOINED
SINGLE_TABLE Strategy (Table Per Hierarchy)
This is default, even if no @Inheritance is noted on Vehicle class.
Even if Vehicle, TwoWheeler and FourWheeler are implemented as separate @Entity, these are not mapped as separate tables. It has mapped everything to base class Vehicle with DTYPE recording the class name.
DTYPE – Discriminator Type

@Entity
@Inheritance(Strategy=InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name="VEHICLE_TYPE", DiscriminatorType.STRING)
Public class Vehicle{ }
@Entity
@DiscriminatorValue("Bike")
Public class TwoWheeler{ }
DiscriminatorType.STRING
DiscriminatorType.INTEGER
DiscriminatorType.CHAR
Note: Discriminator is needed only for Single Class Strategy
Advantages of Single Table Strategy
- Simplest to implement.
- Only one table to deal with.
- Performance wise better than all strategies because no joins or sub-selects need to be performed.
Disadvantages of Single Table Strategy
- Most of the column of table are nullable so the NOT NULL constraint cannot be applied.
- Tables are not normalized.
TABLE_PER_CLASS Strategy (Table Per Concrete class)
@Entity
@Inheritance(Strategy=InheritanceType.TABLE_PER_CLASS)
Public class Vehicle{ }

Here, @GeneratedValue is inherited by all the childs as well. Generated values 1,2,3.
Advantages of Table Per Class Strategy
- You can define NOT NULL constraints on the table.
Disadvantages of Table Per Class Strategy
- Tables are not normalized.
- Select statements require more time to execute as UNION operation is applied.
JOINED Strategy (Table Per Subclass)
@Entity
@Inheritance(Strategy=InheritanceType.JOINED)
Public class Vehicle{ }

Advantages of Joined Table Strategy
- Tables are normalized.
- You can define NOT NULL constraints.
Disadvantages of Joined Table Strategy
- Low performance as it runs OUTER JOIN as well as INNER JOIN in select stements.
@PrimaryKeyJoinColumn(name="ID")
public class Regular_Employee extends Employee{
SessionFactory and Session
SessionFactory
- Reads hibernate config file
- Creates Session Objects
- Heavy weight object, created only once in your application.
Session
- Wraps a JDBC connection
- Main object used to save/retrieve object
- Short lived object
- Retrieved from session factory
What is Hibernate SessionFactory and how to configure it?
- Factory class responsible to read the hibernate config params and connect to the DB and provide Session objects.
- Usually an application has a single SessionFactory instance and threads servicing client requests obtain Session instances from this factory.
- The internal state of a SessionFactory is immutable. Once it is created this internal state is set. This internal state includes all of the metadata about Object/Relational Mapping.
- SessionFactory also provide methods to get the Class metadata and Statistics instance to get the stats of query executions, second level cache details etc.
Classes used in building SessionFactory
I have used following classes for building SessionFactory in hibernate 4.
- Configuration : In place of deprecated AnnotationConfiguration
- StandardServiceRegistryBuilder : In place of deprecated ServiceRegistryBuilder
public class HibernateUtil{
private static SessionFactory sessionFactory = buildSessionFactory();
private static SessionFactory buildSessionFactory() {
try {
if (sessionFactory == null) {
Configuration configuration = new Configuration().configure(HibernateUtil.class.getResource("/hibernate.cfg.xml"));
StandardServiceRegistryBuilder serviceRegistryBuilder = new StandardServiceRegistryBuilder();
serviceRegistryBuilder.applySettings(configuration.getProperties());
ServiceRegistry serviceRegistry = serviceRegistryBuilder.build();
sessionFactory = configuration.buildSessionFactory(serviceRegistry);
}
return sessionFactory;
} catch (Throwable ex) {
System.err.println("Initial SessionFactory creation failed." + ex);
throw new ExceptionInInitializerError(ex);
}
}
public static SessionFactory getSessionFactory() { return sessionFactory; }
public static void shutdown() { getSessionFactory().close(); }
}
Hibernate SessionFactory is thread safe?
Internal state of SessionFactory is immutable, so it’s thread safe. Multiple threads can access it simultaneously to get Session instances.
What is Hibernate Session and how to get it?
- Hibernate Session is the interface between java application layer and hibernate.
- core interface used to perform DB operations.
- Lifecycle of a session is bound by the beginning and end of a transaction.
- Session provide methods to perform create, read, update and delete operations for a persistent object.
- We can execute HQL queries, SQL native queries and create criteria using Session object.
Hibernate Session is thread safe?
Hibernate Session object is not thread safe, every thread should get its own session instance and close it after its work is finished.
What is difference between openSession and getCurrentSession?
getCurrentSession() - returns the session bound to the context. But for this to work, we need to configure it in hibernate configuration file. Since this session object belongs to the hibernate context, we don’t need to close it. Once the session factory is closed, this session object gets closed.
Hibernate Session objects are not thread safe, so we should not use it in multi-threaded environment. We can use it in single threaded environment because it’s relatively faster than opening a new session.
<property name="hibernate.current_session_context_class">thread</property>
openSession()
- Always opens a new session. We should close this session object once we are done with all the database operations. We should open a new session for each request in multi-threaded environment.
- For web application frameworks, we can choose to open a new session for each request or for each session based on the requirement.
openStatelessSession()
- returns instance of StatelessSession.
- StatelessSession in Hibernate does not implement first-level cache and it doesn’t interact with any second-level cache. Since it’s stateless, it doesn’t implement transactional write-behind or automatic dirty checking or do cascading operations to associated entities.
- Collections are also ignored by a stateless session. Operations performed via a stateless session bypass Hibernate’s event model and interceptors. It’s more like a normal JDBC connection and doesn’t provide any benefits that come from using hibernate framework.
- However, stateless session can be a good fit in certain situations. For example where we are loading bulk data into database and we don’t want hibernate session to hold huge data in first-level cache memory.
public class HibernateUtil {
private static final SessionFactory sessionFactory = buildSessionFactory();
private static SessionFactory buildSessionFactory() {
try {
// Create the SessionFactory from hibernate.cfg.xml
return new AnnotationConfiguration().configure(new File("hibernate.cgf.xml")).buildSessionFactory();
} catch (Throwable ex) {
// Make sure you log the exception, as it might be swallowed
System.err.println("Initial SessionFactory creation failed." + ex);
throw new ExceptionInInitializerError(ex);
}
}
public static SessionFactory getSessionFactory() {
return sessionFactory;
}
public static void shutdown() {
// Close caches and connection pools
getSessionFactory().close();
}
}
//Current Session - no need to close Session
currentSession = sessionFactory.getCurrentSession();
//open new session
Session newSession = sessionFactory.openSession();
//perform db operations and close session
newSession.close();
//open stateless session
StatelessSession statelessSession = sessionFactory.openStatelessSession();
//perform stateless db operations and close session
statelessSession.close();
//close session factory
sessionFactory.close();
What is difference between Hibernate Session get() and load() method?
| get() | load() |
|---|---|
| loads the data as soon as it’s called | returns a proxy object and loads data only when actually required |
| Eager loading | support lazy loading. |
| Returns null | throws ObjectNotFoundException when data is not found |
| use get() when we want to make sure data exists in the DB. | should use it only when we know data exists. |
What is difference between Hibernate save(), saveOrUpdate() and persist() methods?
- save() - can be used to save entity to database. Problem with save() is that it can be invoked without a transaction and if we have mapping entities, then only the primary object gets saved causing data inconsistencies. Also save returns the generated id immediately.
- persist() - similar to save with transaction. I feel it’s better than save because we can’t use it outside the boundary of transaction, so all the object mappings are preserved. Also persist doesn’t return the generated id immediately, so data persistence happens when needed.
- saveOrUpdate() - results into insert or update queries based on the provided data. If the data is present in the database, update query is executed. We can use saveOrUpdate() without transaction also, but again you will face the issues with mapped objects not getting saved if session is not flushed.
For example usage of these methods, read Hibernate save vs persist
Suggestion For production code – best practices
It wouldn’t be advisable to try to use above code in production code. Ideally, what you would do is pass VO object to DAO layer, load the entity from the session and update the entity with by copying VO data onto it. This means that the updates take place on a persistent object, and we don’t actually have to call Session.save() or Session.saveOrUpdate() at all.
Once an object is in a persistent state, Hibernate manages updates to the database itself as you change the fields and properties of the object. It’s big relief.
Summary
- Save() method stores an object into the database. It will Persist the given transient instance, first assigning a generated identifier. It returns the id of the entity created.
- SaveOrUpdate() calls either save() or update() on the basis of identifier exists or not. e.g if identifier does not exist, save() will be called or else update() will be called.
- Probably you will get very few chances to actually call save() or saveOrUpdate() methods, as hibernate manages all changes done in persistent objects.
What is use of Hibernate Session merge() call?
Hibernate merge can be used to update existing values, however this method creates a copy from the passed entity object and return it. The returned object is part of persistent context and tracked for any changes, passed object is not tracked.
For example program, read Hibernate merge
refresh()
Sometimes we face situation where we application database is modified with some external application/agent and thus corresponding hibernate entity in your application actually becomes out of sync with it’s database representation i.e. having old data. In this case, you can use session.refresh() method to re-populate the entity with latest data available in database.
- Method merge() does exactly opposite to what refresh() does i.e. It updates the database with values from a detached entity. Refresh method was updating the entity with latest database information. So basically, both are exactly opposite.
- Merging is performed when you desire to have a detached entity changed to persistent state again, with the detached entity’s changes migrated to (or overriding) the database.
- Copy the state of the given object onto the persistent object with the same identifier. If there is no persistent instance currently associated with the session, it will be loaded. Return the persistent instance. If the given instance is unsaved, save a copy of and return it as a newly persistent instance. The given instance does not become associated with the session. This operation cascades to associated instances if the association is mapped with cascade=”merge”.
What will happen if we don’t have no-args constructor in Entity bean?
Hibernate uses Reflection API to create instance of Entity beans, usually when you call get() or load() methods. The method Class.newInstance() is used for this and it requires no-args constructor. So if you won’t have no-args constructor in entity beans, hibernate will fail to instantiate it and you will get HibernateException.
Lazy Loading
Why we should not make Entity Class final?
Hibernate use proxy classes for lazy loading of data, only when it’s needed. This is done by extending the entity bean, if the entity bean will be final then lazy loading will not be possible, hence low performance.
What is Hibernate Proxy and how it helps in lazy loading?
Hibernate uses proxy object to support lazy loading. Basically when you load data from tables, hibernate doesn’t load all the mapped objects. As soon as you reference a child or lookup object via getter methods, if the linked entity is not in the session cache, then the proxy code will go to the database and load the linked object. It uses javassist to effectively and dynamically generate sub-classed implementations of your entity objects.
Get Data by Lazy Loading
In any application, hibernate fetches data from databse either in eager or lazy mode. Hibernate lazy loading refer to strategy when data is loaded lazily, on demand.
Lazy loading is a design pattern commonly used in computer programming to defer initialization of an object until the point at which it is needed. We know that in hibernate lazy loading can be done by specifying “fetch= FetchType.LAZY” in hibernate mapping annotations. e.g.
- The point is that it is applied only when you are defining mapping between two entities. If above entity has been defined in DepartmentEntity then if you fetch DepartmentEntity then EmployeeEntity will be lazy loaded.
- But, what if you want to lazy load DepartmentEntity itself i.e. master entity itself should be lazy loaded.
- This problem can be solved by using getReference() method inside IdentifierLoadAccess class.
@Entity
@Table(name = "Employee", uniqueConstraints = {
@UniqueConstraint(columnNames = "ID"),
@UniqueConstraint(columnNames = "EMAIL")
})
public class EmployeeEntity implements Serializable {
private static final long serialVersionUID = -1798070786993154676 L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID", unique = true, nullable = false)
private Integer employeeId;
//Use the natural id annotation here
@NaturalId(mutable = false)
@Column(name = "EMAIL", unique = true, nullable = false, length = 100)
private String email;
@Column(name = "FIRST_NAME", unique = false, nullable = false, length = 100)
private String firstName;
@Column(name = "LAST_NAME", unique = false, nullable = false, length = 100)
private String lastName;
//Setters and Getters
@ ManyToOne(fetch = FetchType.LAZY)
@JoinColumns({
@JoinColumn(name = "fname", referencedColumnName = "firstname"),
@JoinColumn(name = "lname", referencedColumnName = "lastname")
})
public EmployeeEntity getEmployee() {
return employee;
}
}
I want to lazy load above master entity lazy loaded in my code i.e. I can get reference of entity in one place but might be actually needing it another place. Only when I need it, I want to initialize or load its data. Till the time, I want only the reference.
//Get only the reference of EmployeeEntity for now
EmployeeEntity empGet = (EmployeeEntity) session.byId(EmployeeEntity.class).getReference(1);
System.out.println("No data initialized till now; Lets fetch some data..");
//Now EmployeeEntity will be loaded from database when we need it
System.out.println(empGet.getFirstName());
System.out.println(empGet.getLastName());
why we need it?
- Consider one of common Internet web application: the online store. The store maintains a catalog of products. At the crudest level, this can be modeled as a catalog entity managing a series of product entities. In a large store, there may be tens of thousands of products grouped into various overlapping categories.
- When a customer visits the store, the catalog must be loaded from the database. We probably don’t want the implementation to load every single one of the entities representing the tens of thousands of products to be loaded into memory. For a sufficiently large retailer, this might not even be possible, given the amount of physical memory available on the machine.
- Even if this was possible, it would probably cripple the performance of the site. Instead, we want only the catalog to load, possibly with the categories as well. Only when the user drills down into the categories should a subset of the products in that category be loaded from the database.
- To manage this problem, Hibernate provides a facility called lazy loading. When enabled, an entity’s associated entities will be loaded only when they are directly requested.
How lazy loading solve above problem
Now when we have understood the problem, let’s understand how lazy loading actually helps in real life. If we consider to solve the problem discussed above then we would be accessing a category (or catalog) in below manner:
//Following code loads only a single category from the database:
Category category = (Category)session.get(Category.class,new Integer(42));
However, if all products of this category are accessed, and lazy loading is in effect, the products are pulled from the database as needed. For instance, in the following snippet, the associated product objects will be loaded since it is explicitly referenced in second line.
//Following code loads only a single category from the database
Category category = (Category)session.get(Category.class,new Integer(42));
//This code will fetch all products for category 42 from database - "NOW"
Set<Product> products = category.getProducts();
This solve our problem of loading the products only when they are needed.
How to enable lazy loading in hibernate
Before moving further, it is important to recap the default behavior of lazy loading in case of using hibernate mappings vs annotations.
- The default behavior is to load ‘property values eagerly’ and to load ‘collections lazily’. Contrary to what you might remember if you have used plain Hibernate 2 (mapping files) before, where all references (including collections) are loaded eagerly by default.
- Also note that @OneToMany and @ManyToMany associations are defaulted to LAZY loading; and @OneToOne and @ManyToOne are defaulted to EAGER loading. This is important to remember to avoid any pitfall in future.
To enable lazy loading explicitly you must use “fetch = FetchType.LAZY” on a association which you want to lazy load when you are using hibernate annotations.
A hibernare lazy load example will look like this:
@OneToMany( mappedBy = "category", fetch = FetchType.LAZY )
private Set<ProductEntity> products;
Another attribute parallel to “FetchType.LAZY” is “FetchType.EAGER” which is just opposite to LAZY i.e. it will load association entity as well when owner entity is fetched first time.
How lazy loading works in hibernate
The simplest way that Hibernate can apply lazy load behavior upon the entities and associations is by providing a proxy implementation of them. Hibernate intercepts calls to the entity by substituting a proxy for it derived from the entity’s class. Where the requested information is missing, it will be loaded from the database before control is ceded to the parent entity’s implementation.
Please note that when the association is represented as a collection class, then a wrapper (essentially a proxy for the collection, rather than for the entities that it contains) is created and substituted for the original collection. When you access this collection proxy then what you get inside returned proxy collection are not proxy entities; rather they are actual entities. You need not to put much pressure on understanding this concept because on runtime it hardly matters.
Effect of lazy loading on detached entities
- As we know that hibernate can only access the database via a session, So If an entity is detached from the session and when we try to access an association (via a proxy or collection wrapper) that has not yet been loaded, Hibernate throws a LazyInitializationException.
- The cure is to ensure either that the entity is made persistent again by attaching it to a session or that all of the fields that will be required are accessed (so they are loaded into entity) before the entity is detached from the session.
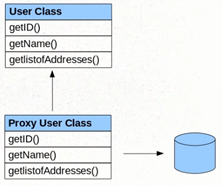
| Default Fetch Type | |
|---|---|
| @OneToOne | FetchType.EAGER |
| @OneToMany | FetchType.LAZY |
| @ManyToOne | FetchType.EAGER |
| @ManyToMany | FetchType.LAZY |
User user = (User) session.get(User.class, id); //List of address not pulled here user.getListOfAddress();
Here query runs to actually fetch from DB.
Lazy initialization: Fetch first level member variables to initialize the proxy.
Proxy Class: Dynamic Subclass of your objects’ class
- Hibernate creates Proxy Class, and to initialize fills in 1st level member variables and returns proxy object.
- getId() internally calls parent.getID() hence difference not noticed by end user.
user = (User) session.get(User.class, id);
session.close();
user.getListOfAddress();
// LazyInitializationException is thrown
@ElementCollection(fetch="FetchType.EAGER")
Still in this case, a proxy object is returned as there might be another collection with LAZY fetchType.
Entity / Persistence LifeCycle States
What are different states of an entity bean?
An entity bean instance can exist is one of the three states.
- Transient: When an object is never persisted or associated with any session, it’s in transient state. Transient instances may be made persistent by calling save(), persist() or saveOrUpdate(). Persistent instances may be made transient by calling delete().
- Persistent: When an object is associated with a unique session, it’s in persistent state. Any instance returned by a get() or load() method is persistent.
- Detached: When an object is previously persistent but not associated with any session, it’s in detached state. Detached instances may be made persistent by calling update(), saveOrUpdate(), lock() or replicate(). The state of a transient or detached instance may also be made persistent as a new persistent instance by calling merge().
As you know that Hibernate works with normal Java objects that your application creates with the new operator. In raw form (without annotations), hibernate will not be able to identify your java classes; but when they are properly annotated with required annotations then hibernate will be able to identify them and then work with them e.g. store in DB, update them etc. These objects can be said to mapped with hibernate.
Given an instance of an object that is mapped to Hibernate, it can be in any one of four different states: transient, persistent, detached, or removed.

Transient Object
![]()
- Transient objects exist in heap memory. Hibernate does not manage transient objects or persist changes to transient objects.
- To persist the changes to a transient object, you would have to ask the session to save the transient object to the database, at which point Hibernate assigns the object an identifier and marks the object as being in persistent state.
Persistent Object
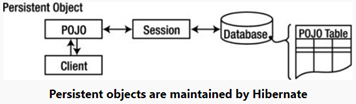
- Persistent objects exist in the database, and Hibernate manages the persistence for persistent objects.
- If fields or properties change on a persistent object, Hibernate will keep the database representation up to date when the application marks the changes as to be committed.
Detached Object
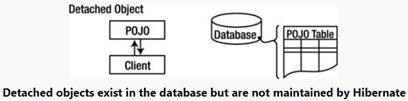
- Detached objects have a representation in the database, but changes to the object will not be reflected in the database, and vice-versa. This temporary separation of the object and the database is shown in image below.
- A detached object can be created by closing the session that it was associated with, or by evicting it from the session with a call to the session’s evict() method.
One reason you might consider doing this would be to read an object out of the database, modify the properties of the object in memory, and then store the results some place other than your database. This would be an alternative to doing a deep copy of the object.
In order to persist changes made to a detached object, the application must reattach it to a valid Hibernate session. A detached instance can be associated with a new Hibernate session when your application calls one of the load, refresh, merge, update(), or save() methods on the new session with a reference to the detached object. After the call, the detached object would be a persistent object managed by the new Hibernate session.
Removed Object
Removed objects are objects that are being managed by Hibernate (persistent objects, in other words) that have been passed to the session’s remove() method. When the application marks the changes held in the session as to be committed, the entries in the database that correspond to removed objects are deleted.
Bullet Points
- Newly created POJO object will be in the transient state. Transient object doesn’t represent any row of the database i.e. not associated with any session object. It’s plain simple java object.
- Persistent object represent one row of the database and always associated with some unique hibernate session. Changes to persistent objects are tracked by hibernate and are saved into database when commit call happen.
- Detached objects are those who were once persistent in past, and now they are no longer persistent. To persist changes done in detached objects, you must reattach them to hibernate session.
- Removed objects are persistent objects that have been passed to the session’s remove() method and soon will be deleted as soon as changes held in the session will be committed to database.
UserDetails user = new UserDetails(); //Transient Object
User.setUserName("Arpit Tripathi");
SessionFactory sf = new Configuration().configure().buildSessionFactory();
Session s = sf.openSession();
s.beginTransaction();
s.save(user); //Persistent
user.setUserName("Update Arpit Tripathi");
s.getTransaction().commit();
s.close;
- Until we pass the object to hibernate, it is a transient object. On calling session.save, the object is handed to hibernate and becomes persistent.
- After session.save(), whatever changes you make will go as update statement. Last state ie. State of object at the time of commit will be reflected in DB.
- Hibernate will watch for changes in persistent objects
- After session.close(), object becomes detached.
Transient – Hibernate doesn’t know about it.
Persistent – Hibernate is tracking it.
Detached – Had been tracked by hibernate.
CRUD (Create / Read / Update / Delete)
session.save(user);
session.get(UserDetails.class, id);
session.delete(user);
user.setName("Updated");
session.update(user);
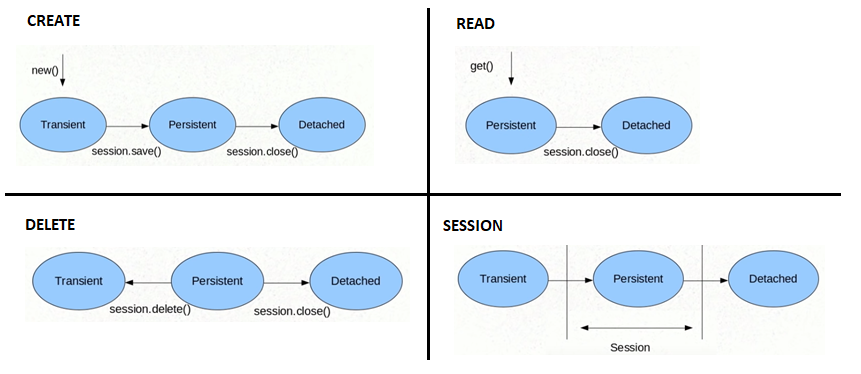
Detached to Persistent
- User may take time hence we have to create a session to fetch and then close it. Here, the object become detached.
- Now user may upfate the a member variable that needs to be saved. To save it, open a new session and call the session.update(user).
session2 = sessionFactory.openSession();
session2.beginTransaction();
session2.update(user);
// Update runs even though nothing changed as session1 was closed making it detached.
// user.setUserName("Updated Users");
session2.getTransaction().commit();
session2.close(); // Now user is a transient object.
To stop this extra update query from running, we would instruct hibernate to run a select query and check if any changes are made. Update only if there are changes.
@Entity
@org.hibernate.annotations.Entity(selectBeforeUpdate=true)
Now, only select query is run for no change scenario.
User.senName("Test");
Session.update(user); // Select + Update Query
Equality
- Requesting a persistent object again from the same Hibernate session returns the same Java instance of a class, which means that you can compare the objects using the standard Java ‘==’ equality syntax.
- If you request a persistent object from more than one Hibernate session, Hibernate will provide distinct instances from each session, and the == operator will return false if you compare these object instances.
- So if you are comparing objects in two different sessions, you will need to implement the equals() method on your Java persistence objects, which you should do as a regular occurrence anyway. (Just don’t forget to override hashCode() along with it.)
Bullet Points
- Requesting a persistent object again from the same Hibernate session returns the “same java instance” of a class.
- Requesting a persistent object from the different Hibernate session returns “different java instance” of a class.
- As a best practice, always implement equals() and hashCode() methods in your hibernate entities; and always compare them using equals() method only.
Hibernate Collections
What is difference between sorted collection and ordered collection, which one is better?
When we use Collection API sorting algorithms to sort a collection, it’s called sorted list. For small collections, it’s not much of an overhead but for larger collections it can lead to slow performance and OutOfMemory errors. Also the entity beans should implement Comparable or Comparator interface for it to work.
If we are using Hibernate framework to load collection data from database, we can use it’s Criteria API to use “order by” clause to get ordered list. Below code snippet shows you how to get it.
List<Employee> empList = session.createCriteria(Employee.class).addOrder(Order.desc("id")).list();
Ordered list is better than sorted list because the actual sorting is done at database level, that is fast and doesn’t cause memory issues.
What are the collection types in Hibernate?
There are five collection types in hibernate used for one-to-many relationship mappings.
- Bag – List/ArrayList (Any order)
- Bag semantic with ID – List/ArrayList (has ID)
- Set - Set
- List – List/ArrayList
- Array -
- Map - Map
Case – 10 user, 10 vehicle, @ManyToMany
Save(u1) // save(v1), save(v2) ……… , save(v10)
Save(u2) // save(v1), save(v2) ……… , save(v10)
.
.
Save(u10) // save(v1), save(v2) ……… , save(v10)
// Here, cascading can be used.
Blob
@Entity
@Table(name = "TBL_IMAGES")
public class ImageWrapper implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID", unique = true, nullable = false)
private Integer id;
@Column(name = "IMAGE_NAME", unique = false, nullable = false, length = 100)
private String imageName;
@Column(name = "DATA", unique = false, nullable = false, length = 100000)
private byte[] data;
//Getters and Setters
}
Inserting blob data into database
Session session = HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
File file = new File("C:\test.png");
byte[] imageData = new byte[(int) file.length()];
try {
FileInputStream fileInputStream = new FileInputStream(file);
fileInputStream.read(imageData);
fileInputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
ImageWrapper image = new ImageWrapper();
image.setImageName("test.jpeg");
image.setData(imageData);
session.save(image); //Save the data
session.getTransaction().commit();
HibernateUtil.shutdown();
Reading the blob data from database
Session session = HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
ImageWrapper imgNew = (ImageWrapper)session.get(ImageWrapper.class, 1);
byte[] bAvatar = imgNew.getData();
try{
FileOutputStream fos = new FileOutputStream("C:\temp\test.png");
fos.write(bAvatar);
fos.close();
}catch(Exception e){
e.printStackTrace();
}
session.getTransaction().commit();
HibernateUtil.shutdown();
Hibernate Queries
How to log hibernate generated sql queries in log files?
We can set below property for hibernate configuration to log SQL queries.
<property name="hibernate.show_sql">true</property>
However we should use it only in Development or Testing environment and turn it off in production environment.
How to implement Joins in Hibernate?
There are various ways to implement joins in hibernate.
- Using associations such as one-to-one, one-to-many etc.
- Using JOIN in the HQL query. There is another form “join fetch” to load associated data simultaneously, no lazy loading.
- We can fire native sql query and use join keyword.
Can we execute native sql query in hibernate?
- Hibernate provide option to execute native SQL queries through the use of SQLQuery object.
- For normal scenarios, it is however not the recommended approach because we loose benefits related to hibernate association and hibernate first level caching.
(Read more at Hibernate Native SQL Query Example.)
What is the benefit of native sql query support in hibernate?
Native SQL Query comes handy when we want to execute database specific queries that are not supported by Hibernate API such as query hints or the CONNECT keyword in Oracle Database.
What is Named SQL Query?
- Hibernate provides Named Query that we can define at a central location and use them anywhere in the code. We can created named queries for both HQL and Native SQL.
- Hibernate Named Queries can be defined in Hibernate mapping files or through the use of JPA annotations @NamedQuery and @NamedNativeQuery.
What are the benefits of Named SQL Query?
- Hibernate Named Query helps us in grouping queries at a central location rather than letting them scattered all over the code.
- Hibernate Named Query syntax is checked when the hibernate session factory is created, thus making the application fail fast in case of any error in the named queries. Hibernate Named Query is global, means once defined it can be used throughout the application.
- However one of the major disadvantage of Named query is that it’s hard to debug, because we need to find out the location where it’s defined.
Native SQL
- Writing the query in DB specific Query Language is called Native SQL.
- After you pass a string containing the SQL query to the createSQLQuery() method, you should associate the SQL result with an existing Hibernate entity, a join, or a scalar result. The SQLQuery interface has addEntity(), addJoin(), and addScalar() methods.
String sql = "select avg(product.price) as avgPrice from Product product";
SQLQuery query = session.createSQLQuery(sql);
query.addScalar("avgPrice",Hibernate.DOUBLE);
List results = query.list();
String sql = "select {supplier.*} from Supplier supplier";
SQLQuery query = session.createSQLQuery(sql);
query.addEntity("supplier", Supplier.class);
List results = query.list();
//Hibernate modifies the SQL and executes the following command against the database:
select Supplier.id as id0_, Supplier.name as name2_0_ from Supplier supplier
SQL Injection
String minUserId = "5"; // User input as string
quryString = "from User Details where userId > "+ minUserId;
Here, user can enter minUserId = “5 or 1=1”;
This is called SQLInjection. To avoid it, we can use parameter binding.
Query q = session.createQuery("from UserDetails where userId > ? and username = ?");
q.setInteger(0, Integer.parseInt(minUserId));
q.setString(1, username);
Query q = session.createQuery("from UserDetails where userId > :userId and username = :username");
q.setInteger("userId", Integer.parseInt(minUserId));
q.setString("username", name);
Named Query
Named queries in hibernate is a technique to group the HQL statements in single location, and lately refer them by some name whenever need to use them. It helps largely in code cleanup because these HQL statements are no longer scattered in whole code.
Apart from above, below are some minor advantages of named queries:
- Fail fast: Their syntax is checked when the session factory is created, making the application fail fast in case of an error.
- Reusable: They can be accessed and used from several places which increase re-usability.
But, you must know that named query really make code less readable and sometimes debugging becomes more hard, as you have to locate the actual query definition being executed and understand that as well.
Performance wise named queries done not make much difference, nor put any excessive cost.
- The cost of transforming a HQL query to SQL is negligible compared to the cost of actually executing the query.
- The memory cost of caching the query is really small. Remember that Hibernate needs to have all the entities meta-data in memory anyway.
Named query definition has two important attributes:
- name: The name of name query by which it will be located using hibernate session.
- query: Here you give the HQL statement to get executed in database.
@Entity
@Table(name = "DEPARTMENT", uniqueConstraints = {
@UniqueConstraint(columnNames = "ID"),
@UniqueConstraint(columnNames = "NAME")
})
@NamedQueries({
@NamedQuery(name = DepartmentEntity.GET_DEPARTMENT_BY_ID, query = DepartmentEntity.GET_DEPARTMENT_BY_ID_QUERY),
@NamedQuery(name = DepartmentEntity.UPDATE_DEPARTMENT_BY_ID, query = DepartmentEntity.UPDATE_DEPARTMENT_BY_ID_QUERY)
})
public class DepartmentEntity implements Serializable {
static final String GET_DEPARTMENT_BY_ID_QUERY = "from DepartmentEntity d where d.id = :id";
public static final String GET_DEPARTMENT_BY_ID = "GET_DEPARTMENT_BY_ID";
static final String UPDATE_DEPARTMENT_BY_ID_QUERY = "UPDATE DepartmentEntity d SET d.name=:name where d.id = :id";
public static final String UPDATE_DEPARTMENT_BY_ID = "UPDATE_DEPARTMENT_BY_ID";
private static final long serialVersionUID = 1 L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID", unique = true, nullable = false)
private Integer id;
}
//Update record using named query
Query query = session.getNamedQuery(DepartmentEntity.UPDATE_DEPARTMENT_BY_ID)
.setInteger("id", 1).setString("name", "Finance");
query.executeUpdate();
//Get named query instance
query = session.getNamedQuery(DepartmentEntity.GET_DEPARTMENT_BY_ID).setInteger("id", 1);
//Get all departments (instances of DepartmentEntity)
DepartmentEntity department = (DepartmentEntity) query.uniqueResult();
Important points:
- Use JPA style query language. e.g. in place of table name, use Entity name.
- Use named queries preferably only for selecting records based on complex conditions. Do not use them excessively, otherwise there is no use of using ORM over simple JDBC.
- Please remember that result of named queries is not cached in secondary cache, only query object itself get cached.
- Make a habit of adding couple of unit testcases whenever you add any named query in code. And run those unit testcases immediately.
- You can not have two named queries with same name in hibernate. Hibernate shows fail fast behavior in this regard and will show error in application start up itself.
Hibernate HQL
What is HQL and what are it’s benefits?
- Hibernate Framework comes with a powerful object-oriented query language – Hibernate Query Language (HQL). It’s very similar to SQL except that we use Objects instead of table names, that makes it closer to OOP.
- Hibernate query language is case-insensitive except for java class and variable names. So SeLeCT is the same as sELEct is the same as SELECT, but com.journaldev.model.Employee is not same as com.journaldev.model.EMPLOYEE.
- The HQL queries are cached but we should avoid it as much as possible, otherwise we will have to take care of associations. However it’s a better choice than native sql query because of Object-Oriented approach.
(Read more at HQL Example.)
What is the benefit of Hibernate Criteria API?
Hibernate provides Criteria API that is more object oriented for querying the database and getting results. We can’t use Criteria to run update or delete queries or any DDL statements. It’s only used to fetch the results from the database using more object-oriented approach.
Some of the common usage of Criteria API are:
- Criteria API provides Projection that we can use for aggregate functions such as sum(), min(), max() etc.
- Criteria API can be used with ProjectionList to fetch selected columns only.
- Criteria API can be used for join queries by joining multiple tables, useful methods are createAlias(), setFetchMode() and setProjection()
- Criteria API can be used for fetching results with conditions, useful methods are add() where we can add Restrictions.
- Criteria API provides addOrder() method that we can use for ordering the results.
(Learn some quick examples at Hibernate Criteria Example.)
Update
UPDATE [VERSIONED]
[FROM] path [[AS] alias] [, ...]
SET property = value [, ...]
[WHERE logicalExpression]
Query query=session.createQuery("update Employee set age=:age where name=:name");
query.setInteger("age", 32);
query.setString("name", "Lokesh Gupta");
int modifications=query.executeUpdate();
- path – fully qualified name of the entity or entities
- alias – used to abbreviate references to specific entities or their properties, and must be used when property names in the query would otherwise be ambiguous.
- VERSIONED – means that the update will update time stamps, if any, that are part of the entity being updated.
- property – names of properties of entities listed in the FROM path.
- logicalExpression – a where clause.
Delete
DELETE removes the details of existing objects from the database. In-memory entities will not be updated to reflect changes resulting from DELETE statements. This also means that Hibernate’s cascade rules will not be followed for deletions carried out using HQL. However, if you have specified cascading deletes at the database level (either directly or through Hibernate, using the @OnDelete annotation), the database will still remove the child rows.
DELETE
[FROM] path [[AS] alias]
[WHERE logicalExpression]
Query query=session.createQuery("delete from Account where accountstatus=:status");
query.setString("status", "purged");
int rowsDeleted=query.executeUpdate();
Insert
An HQL INSERT cannot be used to directly insert arbitrary entities—it can only be used to insert entities constructed from information obtained from SELECT queries (unlike ordinary SQL, in which an INSERT command can be used to insert arbitrary data into a table, as well as insert values selected from other tables).
INSERT INTO path ( property [, ...]) select
Query query=session.createQuery("insert into purged_accounts(id, code, status) "+
"select id, code, status from account where status=:status");
query.setString("status", "purged");
int rowsCopied=query.executeUpdate();
Select
[SELECT [DISTINCT] property [, ...]]
FROM path [[AS] alias] [, ...] [FETCH ALL PROPERTIES]
WHERE logicalExpression
GROUP BY property [, ...]
HAVING logicalExpression
ORDER BY property [ASC | DESC] [, ...]
If FETCH ALL PROPERTIES is used, then lazy loading semantics will be ignored, and all the immediate properties of the retrieved object(s) will be actively loaded (this does not apply recursively).
When the properties listed consist only of the names of aliases in the FROM clause, the SELECT clause can be omitted in HQL. If we are using the JPA with JPQL, one of the differences between HQL and JPQL is that the SELECT clause is required in JPQL.
from clause and aliases
from Product as p
or
from Product product
The from clause is very basic and useful for working directly with objects. However, if you want to work with the object’s properties without loading the full objects into memory, you must use the select clause as explained in next section.
select clause and projection
If you want to obtain the properties of objects in the result set, use the select clause. For instance, we could run a projection query on the products in the database that only returned the names, instead of loading the full object into memory, as follows:
select product.name from Product product
Additionally, we can retrieve the prices and the names for each product in the database, like so:
select product.name, product.price from Product product
If you’re only interested in a few properties, this approach can allow you to reduce network traffic to the database server and save memory on the application’s machine.
Named Parameters
String hql = "from Product where price > :price";
Query query = session.createQuery(hql);
query.setDouble("price",25.0);
List results = query.list();
Paging Through the ResultSet
Query query = session.createQuery("from Product");
query.setFirstResult(1);
query.setMaxResults(2);
List results = query.list();
displayProductsList(results);
Get a Unique Result
String hql = "from Product where price>25.0";
Query query = session.createQuery(hql);
query.setMaxResults(1);
Product product = (Product) query.uniqueResult();
uniqueResult() method on the Query object returns a single object, or null if there are zero results. If there is more than one result, then the uniqueResult() method throws a NonUniqueResultException.
Sorting Results with the ‘order by’ clause
from Product p where p.price>25.0 order by p.price desc
//from Product p order by p.supplier.name asc, p.price asc
select s.name, p.name, p.price from Product p inner join p.supplier as s
//from Product p inner join p.supplier as s
Aggregate Methods
Select count(*) from Product product
The aggregate functions available through HQL include the following:
- avg(property name): The average of a property’s value
- count(property name or *): The number of times a property occurs in the results
- max(property name): The maximum value of the property values
- min(property name): The minimum value of the property values
- sum(property name): The sum total of the property values
Enable Logs and Comments
HQL Logs
The easiest way to see the SQL for a Hibernate HQL query is to enable SQL output in the logs with the “show_sql” property. When you look in your application’s output for the Hibernate SQL statements, they will be prefixed with “Hibernate:”. If you turn your log4j logging up to debug for the Hibernate classes, you will see SQL statements in your log files, along with lots of information about how Hibernate parsed your HQL query and translated it into SQL.
HQL Comments
Tracing your HQL statements through to the generated SQL can be difficult, so Hibernate provides a commenting facility on the Query object that lets you apply a comment to a specific query.
public Query setComment(String comment)
- Hibernate will not add comments to your SQL statements without some additional configuration, even if you use the setComment()method. You will also need to set a Hibernate property, hibernate.use_sql_comments, to true in your Hibernate configuration.
- If you set this property but do not set a comment on the query programatically, Hibernate will include the HQL used to generate the SQL call in the comment. I find this to be very useful for debugging HQL.
- Use commenting to identify the SQL output in your application’s logs if SQL logging is enabled.
Criteria Queries
The criteria query API lets you build nested, structured query expressions in Java, providing a compile-time syntax checking that is not possible with a query language like HQL or SQL.
The Criteria API also includes query by example (QBE) functionality. This lets you supply example objects that contain the properties you would like to retrieve instead of having to step-by-step spell out the components of the query. It also includes projection and aggregation methods, including count().
- Criteria API allows you to build up a criteria query object programmatically; the org.hibernate.Criteria interface defines the available methods for one of these objects.
- Hibernate Session interface contains several overloaded createCriteria()methods.
- Pass the persistent object’s class or its entity name to the createCriteria() method, and hibernate will create a Criteria object that returns instances of the persistence object’s class when your application executes a criteria query.
Criteria crit = session.createCriteria(Product.class);
List<Product> results = crit.list();
Restrictions
Basic Restrictions
equals
Criteria crit = session.createCriteria(Product.class);
crit.add(Restrictions.eq("description","Mouse"));
List<Product> results = crit.list();
not equal to
Criteria crit = session.createCriteria(Product.class);
crit.add(Restrictions.ne("description","Mouse"));
List<Product> results = crit.list();
You cannot use the not-equal restriction to retrieve records with a NULL value in the database for that property (in SQL, and therefore in Hibernate, NULL represents the absence of data, and so cannot be compared with data). If you need to retrieve objects with NULL properties, you will have to use the isNull() restriction.
isNull and isNotNull
Criteria crit = session.createCriteria(Product.class);
crit.add(Restrictions.isNull("name"));
crit.add(Restrictions.isNotNull("name"));
List<Product> results = crit.list();
gt, ge, lt, le
Criteria crit = session.createCriteria(Product.class);
crit.add(Restrictions.gt("price", 25.0));
List<Product> results = crit.list();
like
Criteria crit = session.createCriteria(Product.class);
crit.add(Restrictions.like("name","Mou%",MatchMode.ANYWHERE));
List<Product> results = crit.list();
- ANYWHERE: Anyplace in the string
- END: The end of the string
- EXACT: An exact match
- START: The beginning of the string
Comibining Restrictions
Criteria crit = session.createCriteria(Product.class);
crit.add(Restrictions.lt("price",10.0));
crit.add(Restrictions.ilike("description","mouse", MatchMode.ANYWHERE));
List<Product> results = crit.list();
Criteria crit = session.createCriteria(Product.class);
Criterion priceLessThan = Restrictions.lt("price", 10.0);
Criterion mouse = Restrictions.ilike("description", "mouse", MatchMode.ANYWHERE);
LogicalExpression orExp = Restrictions.or(priceLessThan, mouse);
crit.add(orExp);
List results=crit.list();
Criteria crit = session.createCriteria(Product.class);
Criterion price = Restrictions.gt("price",new Double(25.0));
Criterion name = Restrictions.like("name","Mou%");
LogicalExpression orExp = Restrictions.or(price,name);
crit.add(orExp);
crit.add(Restrictions.ilike("description","blocks%"));
List results = crit.list();
Using Disjunction Objects with Criteria
To create an OR expression with more than two different criteria. The disjunction is more convenient than building a tree of OR expressions in code. To represent an AND expression with more than two criteria, you can use the conjunction() method, although you can easily just add those to the Criteria object. The conjunction can be more convenient than building a tree of AND expressions in code.
Criteria crit = session.createCriteria(Product.class);
Criterion priceLessThan = Restrictions.lt("price", 10.0);
Criterion mouse = Restrictions.ilike("description", "mouse", MatchMode.ANYWHERE);
Criterion browser = Restrictions.ilike("description", "browser", MatchMode.ANYWHERE);
Disjunction disjunction = Restrictions.disjunction();
disjunction.add(priceLessThan);
disjunction.add(mouse);
disjunction.add(browser);
crit.add(disjunction);
List results = crit.list();
sqlRestriction()
sqlRestriction() restriction allows you to directly specify SQL in the Criteria API. It’s useful if you need to use SQL clauses that Hibernate does not support through the Criteria API.
Criteria crit = session.createCriteria(Product.class);
crit.add(Restrictions.sqlRestriction("{alias}.description like 'Mou%'"));
List<Product> results = crit.list();
Paging through the result set
setFirstResult() method takes an integer that represents the first row in your result set, starting with row 0.
Criteria crit = session.createCriteria(Product.class);
crit.setFirstResult(1);
crit.setMaxResults(20);
List<Product> results = crit.list();
Obtain unique result
- Sometimes you know you are going to return only zero or one object from a given query. This could be because you are calculating an aggregate or because your restrictions naturally lead to a unique result.
- If you want obtain a single Object reference instead of a List, the uniqueResult() method on the Criteria object returns an object or null. If there is more than one result, the uniqueResult() method throws a HibernateException.
- The following short example demonstrates having a result set that would have included more than one result, except that it was limited with the setMaxResults() method:
Criteria crit = session.createCriteria(Product.class);
Criterion price = Restrictions.gt("price",new Double(25.0));
crit.setMaxResults(1);
Product product = (Product) crit.uniqueResult();
obtain distinct results
Criteria crit = session.createCriteria(Product.class);
Criterion price = Restrictions.gt("price",new Double(25.0));
crit.setResultTransformer( DistinctRootEntityResultTransformer.INSTANCE )
List<Product> results = crit.list();
Rather than using SELECT DISTINCT with SQL, the distinct result transformer compares each of your results using their default hashCode() methods, and only adds those results with unique hash codes to your result set. This may or may not be the result you would expect from an otherwise equivalent SQL DISTINCT query, so be careful with this.
An additional performance note: the comparison is done in Hibernate’s Java code, not at the database, so non-unique results will still be transported across the network.
sort query results
Criteria crit = session.createCriteria(Product.class);
crit.add(Restrictions.gt("price",10.0));
crit.addOrder(Order.desc("price"));
List<Product> results = crit.list();
You may add more than one Order object to the Criteria object. Hibernate will pass them through to the underlying SQL query. Your results will be sorted by the first order, then any identical matches within the first sort will be sorted by the second order, and so on. Beneath the covers, Hibernate passes this on to an SQL ORDER BY clause after substituting the proper database column name for the property.
perform associations (joins)
The association works when going from either one-to-many or from many-to-one. First, we will demonstrate how to use one-to-many associations to obtain suppliers who sell products with a price over $25. Notice that we create a new Criteria object for the products property, add restrictions to the products’ criteria we just created, and then obtain the results from the supplier Criteria object.
Criteria crit = session.createCriteria(Supplier.class);
Criteria prdCrit = crit.createCriteria("products");
prdCrit.add(Restrictions.gt("price",25.0));
List results = crit.list();
Going the other way, we obtain all the products from the supplier MegaInc using many-to-one associations:
Criteria crit = session.createCriteria(Product.class);
Criteria suppCrit = crit.createCriteria("supplier");
suppCrit.add(Restrictions.eq("name","Hardware Are We"));
List results = crit.list();
projections and aggregates
Instead of working with objects from the result set, you can treat the results from the result set as a set of rows and columns, also known as a projection of the data. This is similar to how you would use data from a SELECT query with JDBC.
Single Aggregate ( Getting Row Count )
Criteria crit = session.createCriteria(Product.class);
crit.setProjection(Projections.rowCount());
List<Long> results = crit.list();
- avg(String propertyName): Gives the average of a property’s value
- count(String propertyName): Counts the number of times a property occurs
- countDistinct(String propertyName): Counts the number of unique values the property contains
- max(String propertyName): Calculates the maximum value of the property values
- min(String propertyName): Calculates the minimum value of the property values
- sum(String propertyName): Calculates the sum total of the property values
Multiple Aggregates
Criteria crit = session.createCriteria(Product.class);
ProjectionList projList = Projections.projectionList();
projList.add(Projections.max("price"));
projList.add(Projections.min("price"));
projList.add(Projections.avg("price"));
projList.add(Projections.countDistinct("description"));
crit.setProjection(projList);
List<object[]> results = crit.list();
Getting Selected Columns
Another use of projections is to retrieve individual properties, rather than entities.
Criteria crit = session.createCriteria(Product.class);
ProjectionList projList = Projections.projectionList();
projList.add(Projections.property("name"));
projList.add(Projections.property("description"));
crit.setProjection(projList);
crit.addOrder(Order.asc("price"));
List<object[]> results = crit.list();
query by example (QBE)
In QBE, instead of programmatically building a Criteria object with Criterion objects and logical expressions, you can partially populate an instance of the object. You use this instance as a template and have Hibernate build the criteria for you based upon its values.
For instance, if we have a user database, we can construct an instance of a user object, set the property values for type and creation date, and then use the Criteria API to run a QBE query. Hibernate will return a result set containing all user objects that match the property values that were set. Behind the scenes, Hibernate inspects the Example object and constructs an SQL fragment that corresponds to the properties on the Example object.
Criteria crit = session.createCriteria(Supplier.class);
Supplier supplier = new Supplier();
supplier.setName("MegaInc");
crit.add(Example.create(supplier));
List results = crit.list();
Too many properties causing too many .add() hence use Query by Example.
Primary and null values are neglected while pulling up the data in the QBE.
- example.excludeProperty(“userName”);
- exampleUser.setUserName(“User1%”);
- example.enableLike();
Hibernate Cache
Hibernate Cache can be very useful in gaining fast application performance if used correctly. The idea behind cache is to reduce the number of database queries, hence reducing the throughput time of the application.
First Level Cache
- Hibernate first level cache is associated with the Session object.
- enabled by default and there is no way to disable it. However, hibernate provides methods through which we can delete selected objects from the cache or clear the cache completely.
- Any object cached in a session will not be visible to other sessions and when the session is closed, all the cached objects will also be lost.
Second Level Cache
- Hibernate Second Level cache is disabled by default but we can enable it through configuration.
- Currently EHCache and Infinispan provides implementation for Hibernate Second level cache and we can use them.
Query Cache
- Hibernate can also cache result set of a query.
- Hibernate Query Cache doesn’t cache the state of the actual entities in the cache; it caches only identifier values and results of value type. So, it should always be used in conjunction with the second-level cache.
What is Query Cache in Hibernate?
Hibernate implements a cache region for queries resultset that integrates closely with the hibernate second-level cache. This is an optional feature and requires additional steps in code. This is only useful for queries that are run frequently with the same parameters. First of all we need to configure below property in hibernate configuration file.
<property name="hibernate.cache.use_query_cache">true</property>
And in code, we need to use setCacheable(true) method of Query, quick example looks like below.
Query query = session.createQuery("from Employee");
query.setCacheable(true);
query.setCacheRegion("ALL_EMP");
First Level Cache
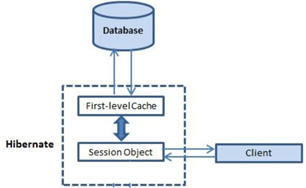
//Open the hibernate session
Session session = HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
//fetch the department entity from database first time
DepartmentEntity department = (DepartmentEntity) session.load(DepartmentEntity.class, new Integer(1));
System.out.println(department.getName());
//fetch the department entity again
department = (DepartmentEntity) session.load(DepartmentEntity.class, new Integer(1));
System.out.println(department.getName());
session.getTransaction().commit();
HibernateUtil.shutdown();
Here, second “session.load()” statement does not execute select query again and load the department entity directly.
But if we use 2 different session objects to load, then, both the time retrieval will happen.
- We can use session evict() method to remove a single object from the hibernate first level cache.
- We can use session clear() method to clear the cache i.e delete all the objects from the cache.
- We can use session contains() method to check if an object is present in the hibernate cache or not, if the object is found in cache, it returns true or else it returns false.
- Since hibernate cache all the objects into session first level cache, while running bulk queries or batch updates it’s necessary to clear the cache at certain intervals to avoid memory issues.
Second Level Cache
Fist level cache: This is enabled by default and works in session scope.
Second level cache: This is apart from first level cache which is available to be used globally in session factory scope.
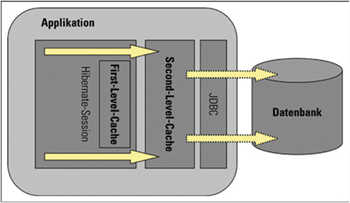
- Above statement means, second level cache is created in session factory scope and is available to be used in all sessions which are created using that particular session factory.
- It also means that once session factory is closed, all cache associated with it die and cache manager also closed down. Further, It also means that if you have two instances of session factory (normally no application does that), you will have two cache managers in your application and while accessing cache stored in physical store, you might get unpredictable results like cache-miss.
How to configure Hibernate Second Level Cache using EHCache?
- EHCache is the best choice for utilizing hibernate second level cache.
- Following steps are required to enable EHCache in hibernate application.
Caching Strategies
- Read Only: This caching strategy should be used for persistent objects that will always read but never updated. It’s good for reading and caching application configuration and other static data that are never updated. This is the simplest strategy with best performance because there is no overload to check if the object is updated in database or not.
- Read Write: It’s good for persistent objects that can be updated by the hibernate application. However if the data is updated either through backend or other applications, then there is no way hibernate will know about it and data might be stale. So while using this strategy, make sure you are using Hibernate API for updating the data.
- Nonrestricted Read Write: If the application only occasionally needs to update data and strict transaction isolation is not required, a nonstrict-read-write cache might be appropriate.
- Transactional: The transactional cache strategy provides support for fully transactional cache providers such as JBoss TreeCache. Such a cache can only be used in a JTA environment and you must specify hibernate.transaction.manager_lookup_class.
Steps For Enabling Cachce
Step 1. Add hibernate-ehcache dependency in your maven project, if it’s not maven then add corresponding jars.
<!-- EHCache Core APIs -->
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache-core</artifactId>
<version>2.6.9</version>
</dependency>
<!-- Hibernate EHCache API -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-ehcache</artifactId>
<version>4.3.5.Final</version>
</dependency>
<!-- EHCache uses slf4j for logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.5</version>
</dependency>
Step 2. Add below properties in hibernate configuration file.
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
<!-- For singleton factory -->
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.SingletonEhCacheRegionFactory</property>
<!-- enable second level cache and query cache -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<property name="hibernate.cache.use_query_cache">true</property>
<property name="net.sf.ehcache.configurationResourceName">/myehcache.xml</property>
Step 3. Create EHCache configuration file, a sample file myehcache.xml would look like below.
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="ehcache.xsd" updateCheck="true"
monitoring="autodetect" dynamicConfig="true">
<diskStore path="java.io.tmpdir/ehcache" />
<defaultCache maxEntriesLocalHeap="10000" eternal="false"
timeToIdleSeconds="120" timeToLiveSeconds="120" diskSpoolBufferSizeMB="30"
maxEntriesLocalDisk="10000000" diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU" statistics="true">
<persistence strategy="localTempSwap" />
</defaultCache>
<cache name="employee" maxEntriesLocalHeap="10000" eternal="false"
timeToIdleSeconds="5" timeToLiveSeconds="10">
<persistence strategy="localTempSwap" />
</cache>
<cache name="org.hibernate.cache.internal.StandardQueryCache"
maxEntriesLocalHeap="5" eternal="false" timeToLiveSeconds="120">
<persistence strategy="localTempSwap" />
</cache>
<cache name="org.hibernate.cache.spi.UpdateTimestampsCache"
maxEntriesLocalHeap="5000" eternal="true">
<persistence strategy="localTempSwap" />
</cache>
</ehcache>
- diskStore: EHCache stores data into memory but when it starts overflowing, it start writing data into file system. We use this property to define the location where EHCache will write the overflown data.
- defaultCache: It’s a mandatory configuration, it is used when an Object need to be cached and there are no caching regions defined for that.
- cache name=”employee”: We use cache element to define the region and it’s configurations. We can define multiple regions and their properties, while defining model beans cache properties, we can also define region with caching strategies. The cache properties are easy to understand and clear with the name.
- Cache regions org.hibernate.cache.internal.StandardQueryCache and org.hibernate.cache.spi.UpdateTimestampsCache are defined because EHCache was giving warning to that.
Step 4. Annotate entity beans with @Cache annotation and caching strategy to use. For example,
import org.hibernate.annotations.Cache;
import org.hibernate.annotations.CacheConcurrencyStrategy;
@Entity
@Table(name = "ADDRESS")
@Cache(usage=CacheConcurrencyStrategy.READ_ONLY, region="employee")
public class Address {
}
That’s it, we are done. Hibernate will use the EHCache for second level caching, read Hibernate EHCache Example for a complete example with explanation.
Session session = SessionFactory.openSession();
Query query = session.createQuery("FROM EMPLOYEE");
query.setCacheable(true);
List users = query.list();
SessionFactory.closeSession();
Session session = SessionFactory.openSession();
Query query = session.createQuery("FROM EMPLOYEE");
query.setCacheable(true);
query.setCacheRegion("employee");
List users = query.list();
SessionFactory.closeSession();
Hibernate Transaction Management
How transaction management works in Hibernate?
- Transaction management is very easy in hibernate because most of the operations are not permitted outside of a transaction. So after getting the session from SessionFactory, we can call session beginTransaction() to start the transaction.
- This method returns the Transaction reference that we can use later on to either commit or rollback the transaction.
- Overall hibernate transaction management is better than JDBC transaction management because we don’t need to rely on exceptions for rollback. Any exception thrown by session methods automatically rollback the transaction.
What is HibernateTemplate class?
- When Spring and Hibernate integration started, Spring ORM provided two helper classes –
HibernateDaoSupportandHibernateTemplate. The reason to use them was to get the Session from Hibernate and get the benefit of Spring transaction management. However from Hibernate 3.0.1, we can useSessionFactorygetCurrentSession() method to get the current session and use it to get the spring transaction management benefits. If you go through above examples, you will see how easy it is and that’s why we should not use these classes anymore. - One other benefit of
HibernateTemplatewas exception translation but that can be achieved easily by using@Repositoryannotation with service classes, shown in above spring mvc example. This is a trick question to judge your knowledge and whether you are aware of recent developments or not.
Hibernate C3P0 Connection Pool
By default, Hibernate uses JDBC connections in order to interact with a database. Creating these connections is expensive—probably the most expensive single operation Hibernate will execute in a typical-use case. Since JDBC connection management is so expensive that possibly you will advise to use a pool of connections, which can open connections ahead of time (and close them only when needed, as opposed to “when they’re no longer used”).
Thankfully, Hibernate is designed to use a connection pool by default, an internal implementation. However, Hibernate’s built-in connection pooling isn’t designed for production use. In production, you would use an external connection pool by using either a database connection provided by JNDI or an external connection pool configured via parameters and classpath.
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>4.3.6.Final</version>
</dependency>
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency>
<property name="hibernate.c3p0.min_size">10</property><property name="hibernate.c3p0.min_size">10</property>
<property name="hibernate.c3p0.max_size">20</property>
<property name="hibernate.c3p0.acquire_increment">1</property>
<property name="hibernate.c3p0.idle_test_period">3000</property>
<property name="hibernate.c3p0.max_statements">50</property>
<property name="hibernate.c3p0.timeout">1800</property>
Hibernate Validations
What is Hibernate Validator Framework?
- Data validation is integral part of any application. You will find data validation at presentation layer with the use of Javascript, then at the server side code before processing it. Also data validation occurs before persisting it, to make sure it follows the correct format.
- Validation is a cross cutting task, so we should try to keep it apart from our business logic. That’s why JSR303 and JSR349 provides specification for validating a bean by using annotations. Hibernate Validator provides the reference implementation of both these bean validation specs.
<!-- Java bean validation API - Spec -->
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
<version>2.0.1.Final</version>
</dependency>
<!-- Hibernate validator - Bean validation API Implementation -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>6.0.11.Final</version>
</dependency>
<!-- Verify validation annotations usage at compile time -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator-annotation-processor</artifactId>
<version>6.0.11.Final</version>
</dependency>
<!-- Unified Expression Language - Spec -->
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>3.0.1-b06</version>
</dependency>
<!-- Unified Expression Language - Implementation -->
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>javax.el</artifactId>
<version>2.2.6</version>
</dependency>
@NotNull(message = "Please enter id")
private Long id;
@Size(max = 20, min = 3, message = "{user.name.invalid}")
@NotEmpty(message = "Please enter name")
private String name;
@Email(message = "{user.email.invalid}")
@NotEmpty(message = "Please enter email")
private String email;
Validation annotations
Bean validation annotations
| ANNOTATION | DESCRIPTION |
|---|---|
| @Digits(integer=, fraction=) | Checks whether the annotated value is a number having up to integer digits and fraction fractional digits. |
| Checks whether the specified character sequence is a valid email address. | |
| @Max(value=) | Checks whether the annotated value is less than or equal to the specified maximum. |
| @Min(value=) | Checks whether the annotated value is higher than or equal to the specified minimum |
| @NotBlank | Checks that the annotated character sequence is not null and the trimmed length is greater than 0. |
| @NotEmpty | Checks whether the annotated element is not null nor empty. |
| @Null | Checks that the annotated value is null |
| @NotNull | Checks that the annotated value is not null |
| @Pattern(regex=, flags=) | Checks if the annotated string matches the regular expression regex considering the given flagmatch |
| @Size(min=, max=) | Checks if the annotated element’s size is between min and max (inclusive) |
| @Negative | Checks if the element is strictly negative. Zero values are considered invalid. |
| @NegativeOrZero | Checks if the element is negative or zero. |
| @Future | Checks whether the annotated date is in the future. |
| @FutureOrPresent | Checks whether the annotated date is in the present or in the future. |
| @PastOrPresent | Checks whether the annotated date is in the past or in the present. |
Hibernate validator specific annotations
| ANNOTATION | DESCRIPTION |
|---|---|
| @CreditCardNumber( ignoreNonDigitCharacters=) | Checks that the annotated character sequence passes the Luhn checksum test. Note, this validation aims to check for user mistakes, not credit card validity! |
| @Currency(value=) | Checks that the currency unit of the annotated javax.money.MonetaryAmount is part of the specified currency units. |
| @EAN | Checks that the annotated character sequence is a valid EAN barcode. The default is EAN-13. |
| @ISBN | Checks that the annotated character sequence is a valid ISBN. |
| @Length(min=, max=) | Validates that the annotated character sequence is between min and max included. |
| @Range(min=, max=) | Checks whether the annotated value lies between (inclusive) the specified minimum and maximum. |
| @UniqueElements | Checks that the annotated collection only contains unique elements. |
| @URL | Checks if the annotated character sequence is a valid URL according to RFC2396. |
public class User {
@NotNull(message = "Please enter id")
private Long id;
@Size(max = 20, min = 3, message = "{user.name.invalid}")
@NotEmpty(message = "Please enter name")
private String name;
@Email(message = "{user.email.invalid}")
@NotEmpty(message = "Please enter email")
private String email;
public User(Long id, String name, String email) {
super();
this.id = id;
this.name = name;
this.email = email;
}
//Getters and Setters
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", email=" + email + "]";
}
}
public class TestHibernateValidator{
@Inject
@HibernateValidator
private static ValidatorFactory validatorFactory;
@Inject
@HibernateValidator
private static Validator validator;
public static void main(String[] args) {
//Create ValidatorFactory which returns validator
validatorFactory = Validation.buildDefaultValidatorFactory();
//It validates bean instances
validator = validatorFactory.getValidator();
User user = new User(null, "1", "abcgmail.com");
//Validate bean
Set<ConstraintViolation<User>> constraintViolations = validator.validate(user);
//Show errors
if (constraintViolations.size() > 0) {
for (ConstraintViolation<User> violation : constraintViolations) {
System.out.println(violation.getMessage());
}
} else {
System.out.println("Valid Object");
}
}
}
//Output:
'1' is an invalid name. It must be minimum 3 chars and maximum 20 chars.
Invalid Email
// ValidationMessages.properties
user.name.invalid='${validatedValue}' is an invalid name. It must be minimum {min} chars and maximum {max} chars.
user.email.invalid=Invalid Email
Hibernate - Misc
What is the benefit of Hibernate Tools Eclipse plugin?
Hibernate Tools plugin helps us in writing hibernate configuration and mapping files easily. The major benefit is the content assist to help us with properties or xml tags to use. It also validates them against the Hibernate DTD files, so we know any mistakes before hand.
(Learn how to install and use at Hibernate Tools Eclipse Plugin.)
Which design patterns are used in Hibernate framework?
Some of the design patterns used in Hibernate Framework are:
- Domain Model Pattern – An object model of the domain that incorporates both behavior and data.
- Data Mapper – A layer of Mappers that moves data between objects and a database while keeping them independent of each other and the mapper itself.
- Proxy Pattern for lazy loading
- Factory pattern in SessionFactory
Why we are using JPA Annotation instead of Hibernate ? For example, why we are not using this org.hibernate.annotations.Entity?
- JPA is a standard specification. Hibernate is an implementation of the JPA specification.
- Hibernate implements all of the JPA annotations.
- The Hibernate team recommends the use of JPA annotations as a best practice.
What are best practices to follow with Hibernate framework?
Some of the best practices to follow in Hibernate are:
- Always check the primary key field access, if it’s generated at the database layer then you should not have a setter for this.
- By default hibernate set the field values directly, without using setters. So if you want hibernate to use setters, then make sure proper access is defined as @Access(value=AccessType.PROPERTY).
- If access type is property, make sure annotations are used with getter methods and not setter methods. Avoid mixing of using annotations on both filed and getter methods.
- Use native sql query only when it can’t be done using HQL, such as using database specific feature.
- If you have to sort the collection, use ordered list rather than sorting it using Collection API.
- Use named queries wisely, keep it at a single place for easy debugging. Use them for commonly used queries only. For entity specific query, you can keep them in the entity bean itself.
- For web applications, always try to use JNDI DataSource rather than configuring to create connection in hibernate.
- Avoid Many-to-Many relationships, it can be easily implemented using bidirectional One-to-Many and Many-to-One relationships.
- For collections, try to use Lists, maps and sets. Avoid array because you don’t get benefit of lazy loading.
- Do not treat exceptions as recoverable, roll back the Transaction and close the Session. If you do not do this, Hibernate cannot guarantee that in-memory state accurately represents the persistent state.
- Prefer DAO pattern for exposing the different methods that can be used with entity bean
- Prefer lazy fetching for associations
How to integrate log4j logging in hibernate application?
Hibernate 4 uses JBoss logging rather than slf4j used in earlier versions. For log4j configuration, we need to follow below steps.
- Add log4j dependencies for maven project, if not maven then add corresponding jar files.
- Create log4j.xml configuration file or log4j.properties file and keep it in the classpath. You can keep file name whatever you want because we will load it in next step.
- For standalone projects, use static block to configure log4j using
DOMConfiguratororPropertyConfigurator. For web applications, you can use ServletContextListener to configure it. That’s it, our setup is ready. Createorg.apache.log4j.Loggerinstance in the java classes and start logging.
(For complete example code, you should go through Hibernate log4j example and Servlet log4j example.)
How to use application server JNDI DataSource with Hibernate framework?
For web applications, it’s always best to allow servlet container to manage the connection pool. That’s why we define JNDI resource for DataSource and we can use it in the web application. It’s very easy to use in Hibernate, all we need is to remove all the database specific properties and use below property to provide the JNDI DataSource name.
<property name="hibernate.connection.datasource">java:comp/env/jdbc/MyLocalDB</property>
(For a complete example, go through Hibernate JNDI DataSource Example.)
How to integrate Hibernate and Spring frameworks?
Spring is one of the most used Java EE Framework and Hibernate is the most popular ORM framework. That’s why Spring Hibernate combination is used a lot in enterprise applications. The best part with using Spring is that it provides out-of-box integration support for Hibernate with Spring ORM module. Following steps are required to integrate Spring and Hibernate frameworks together.
- Add hibernate-entitymanager, hibernate-core and spring-orm dependencies.
- Create Model classes and corresponding DAO implementations for database operations. Note that DAO classes will use SessionFactory that will be injected by Spring Bean configuration.
- If you are using Hibernate 3, you need to configure
org.springframework.orm.hibernate3.LocalSessionFactoryBeanororg.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBeanin Spring Bean configuration file. For Hibernate 4, there is single classorg.springframework.orm.hibernate4.LocalSessionFactoryBeanthat should be configured. - Note that we don’t need to use Hibernate Transaction Management, we can leave it to Spring declarative transaction management using
@Transactionalannotation.
(For complete example go through Spring Hibernate Integration and Spring MVC Hibernate Integration.)
n+1 select problem
Let’s say you have a collection of Car objects (database rows), and each Car has a collection of Wheel objects (also rows). In other words, Car -> Wheel is a 1-to-many relationship.
Now, let’s say you need to iterate through all the cars, and for each one, print out a list of the wheels. The naive O/R implementation would do the following:
SELECT * FROM Cars;
And then for each Car:
SELECT * FROM Wheel WHERE CarId = ?
In other words, you have one select for the Cars, and then N additional selects, where N is the total number of cars. Alternatively, one could get all wheels and perform the lookups in memory:
SELECT * FROM Wheel
This reduces the number of round-trips to the database from N+1 to 2.
Most ORM tools give you several ways to prevent N+1 selects.
- Basically, when using an ORM like NHibernate or EntityFramework, if you have a one-to-many (master-detail) relationship, and want to list all the details per each master record, you have to make N + 1 query calls to the database, “N” being the number of master records: 1 query to get all the master records, and N queries, one per master record, to get all the details per master record.
- More database query calls –> more latency time –> decreased application/database performance.
- However, ORM’s have options to avoid this problem, mainly using “joins”.
- This makes the first select and more 1 select by each N car, that’s why it’s called n+1 problem.
- To avoid this, make the association fetch as eager, so that hibernate loads data with a join.
- But attention, if many times you don’t access associated Wheels, it’s better to keep it LAZY or change fetch type with Criteria.
Store Procedure Call
Native SQL – createSQLQuery
Query query = session.createSQLQuery(
"CALL GetStocks(:stockCode)")
.addEntity(Stock.class)
.setParameter("stockCode", "7277");
List result = query.list();
for(int i=0; i<result.size(); i++){
Stock stock = (Stock)result.get(i);
System.out.println(stock.getStockCode());
}
NamedNativeQuery in annotation
@NamedNativeQueries({
@NamedNativeQuery(
name = "callStockStoreProcedure",
query = "CALL GetStocks(:stockCode)",
resultClass = Stock.class
)
})
@Entity
@Table(name = "stock")
public class Stock implements java.io.Serializable {
Query query = session.getNamedQuery("callStockStoreProcedure")
.setParameter("stockCode", "7277");
List result = query.list();
for(int i=0; i<result.size(); i++){
Stock stock = (Stock)result.get(i);
System.out.println(stock.getStockCode());
}