- Introduction
- Collections Framework FAQ
- What is Collection related features in Java 8?
- Why Collection interface doesn’t extend Cloneable and Serializable interfaces?
- What is the root interface in collection hierarchy?
- Difference between Collection and Collections?
- Why can’t we write code as
List<Number> numbers = new ArrayList<Integer>();? - Why can’t we create generic array? or write code as
List<Integer>[] array = new ArrayList<Integer>[10];?
- Collection Interface
- List Interface
- ArrayList class
- Similarities between Array and ArrayList
- LinkedList Class
- Set Interface
- Why Hashcode 31?
- Queue Interface
- Deque Interface
- Iterator
- Spliterators
- Map Interface
- SortedMap Interface
- NavigableMap Interface
- Map.Entry Interface
- Map Classes
- HashMap
- LinkedHashMap
- Other Maps
- Comparator
- Collections class
- Arrays class
- Collections.sort algorithm
- Legacy Classes
- Concurrent Collection Classes
- TODO
Introduction
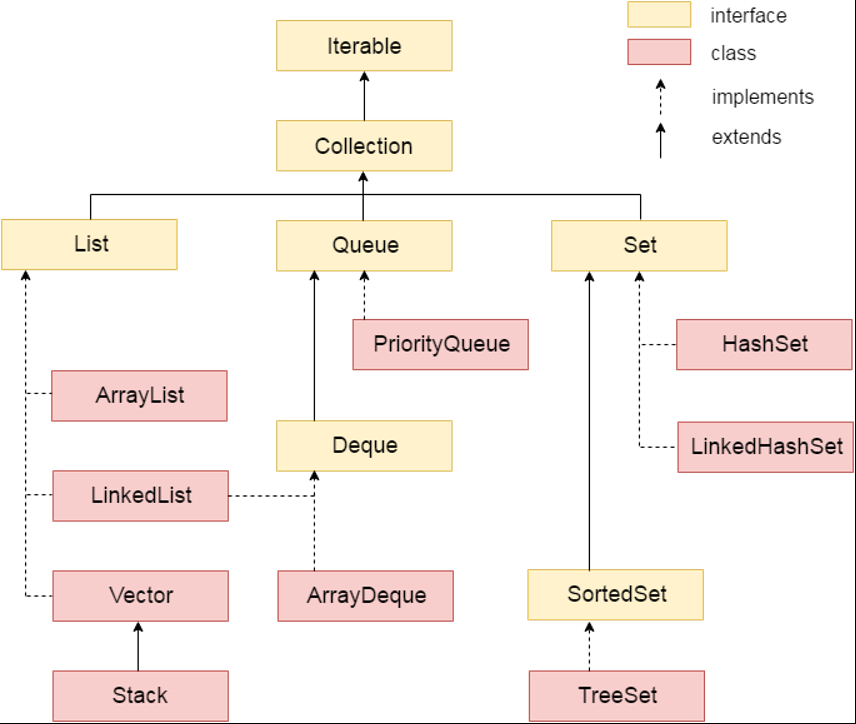
- Framework - Represents set of classes and interface providing readymade architecture.
- Java Collections framework - to store and manipulate the group of objects in a standardized way.
- Collection - represents a single unit of objects i.e. a group.
- All data operations can be performed by Java Collections - searching, sorting, insertion, manipulation, deletion etc..
java.util.*package
Collections Framework Goals
- High-performance
- Interoperatbility
- Easy to adapt or extend - standard implementations.
Benefits of collections framework
- Reduced development effort.
- enhanced code quality, already well tested.
- Reduced code maintenance efforts, shipped with JDK.
- Reusability and Interoperability
- Collections class – contains static method Algorithms for collections. (generic)
- iterator - standardized way of accessing the elements of a collection, provides a means of enumerating its contents.
- JDK 8
- a Spliterator parallel iteration.
- iterator interfaces for primitive types, PrimitiveIterator and PrimitiveIterator.OfDouble.
- Collections framework also defines several map interfaces and classes.
Are Maps Collection?
If not, why put them in Collections Framework?
- Maps are part of Collections Framework, but they are not “collections” in the strict use of the term.
- You can obtain a collection-view of a map.
- Maps - store key/value pairs.
- Eventually they also represent a way of effectively storing the data hence kept in collection framework.
Summary
| collection | Base class | Base interfaces | Duplicate | Ordered | Sorted | Thread-safe |
|---|---|---|---|---|---|---|
| ArrayList<E> | AbstractList<E> | List<E> | Yes | Yes | No | No |
| LinkedList<E> | AbstractSequentialList<E> | List<E> Deque<E> | Yes | Yes | No | No |
| Vector<E> | AbstractList<E> | List<E> | Yes | Yes | No | Yes |
| HashSet<E> | AbstractSet<E> | Set<E> | No | No | No | No |
| LinkedHashSet<E> | HashSet<E> | Set<E> | No | Yes | No | No |
| TreeSet<E> | AbstractSet<E> | Set<E> NavigableSet<E> SortedSet<E> | No | Yes | Yes | No |
| Hashtable<K, V> | Dictionary<K, V> | Map<K, V> | No | No | No | Yes |
| HashMap<K, V> | AbstractMap<K, V> | Map<K, V> | No | No | No | No |
| LinkedHashMap<K, V> | HashMap<K, V> | Map<K, V> | No | Yes | No | No |
| TreeMap<K, V> | AbstractMap<K, V> | Map<K, V> NavigableMap<K, V> SortedMap<K, V> | No | Yes | Yes | No |
- All lists allow duplicate elements which are ordered by index. All list elements are not sorted.
- All sets and maps do not allow duplicate elements.
- Generally, sets and maps do not sort its elements, except TreeSet and TreeMap – which sort elements by natural order or by a comparator.
- Generally, elements within sets and maps are not ordered, except LinkedHashSet and LinkedHashMap - elements ordered by insertion order.
- There are only two collections are thread-safe: Vector and Hastable. The rest is not thread-safe.
Collections Framework FAQ
What is Collection related features in Java 8?
- Stream API - sequential and parallel processing
- forEach() - Iterable interface.
- forEachRemaining(Consumer action), Map replaceAll(), compute(), merge() methods.
Why Collection interface doesn’t extend Cloneable and Serializable interfaces?
- Collection interface specifies group of Objects known as elements.
- Actual implementations decide its behaviour, ex. set doesn’t allow duplicate but list does.
- Only implementations decide if they should be cloned or serialized and how.
- So, mandating cloning and serialization in all implementations is actually less flexible and more restrictive.
What is the root interface in collection hierarchy?
- Root interface in collection hierarchy is Collection interface.
- Few interviewers may argue that Collection interface extends Iterable interface. So iterable should be the root interface.
- But you should reply iterable interface present in
java.langpackage not in java.util package.
- But you should reply iterable interface present in
Difference between Collection and Collections?
Collection is an interface while Collections is a java class.
Why can’t we write code as List<Number> numbers = new ArrayList<Integer>();?
- Generics doesn’t support sub-typing because it will cause issues in achieving type safety.
- If Allowed, sample code would have caused ClassCastException at runtime while traversing the list of Long.
List<Long> listLong = new ArrayList<Long>();
listLong.add(Long.valueOf(10));
List<Number> listNumbers = listLong; // compiler error
listNumbers.add(Double.valueOf(1.23));
Why can’t we create generic array? or write code as List<Integer>[] array = new ArrayList<Integer>[10];?
- arrays are covariant, but generics are invariant.
- array carry type information of its elements at runtime, this information is used at runtime to throw
ArrayStoreExceptionif elements type doesn’t match to the defined type. Since generics type information gets erased at runtime by Type Erasure, the array store check would have been passed where it should have failed, hence Generics are invariant.
Covariant
you can assign subclass type array to its superclass array reference.
Object objectArray[] = new Integer[10]; // it will work fine
Invariant
cannot assign subclass type generic to its super class generic reference because in generics any two distinct types are neither a subtype nor a supertype.
List<Object> objectList = new ArrayList<Integer>(); // won't compile
List<Integer> arrayOfIntegerList[] = new ArrayList<>[10]; // compile time error !!
If Allowed, the below code will throw ClassCastException at runtime.
List<Integer> arrayOfIdList[] = new ArrayList<Integer>[10]; // if generic array creation is legal.
List<String> nameList = new ArrayList<String>();
Object objArray[] = arrayOfIdList; // that is allowed because arrays are covariant
objArray[0] = nameList;
Integer id = objArray[0].get(0);
Here one of the major purposes of generic is failed (i.e., compile time strict type checking). Therefore, to address this problem compile time error gets generated at line 1.
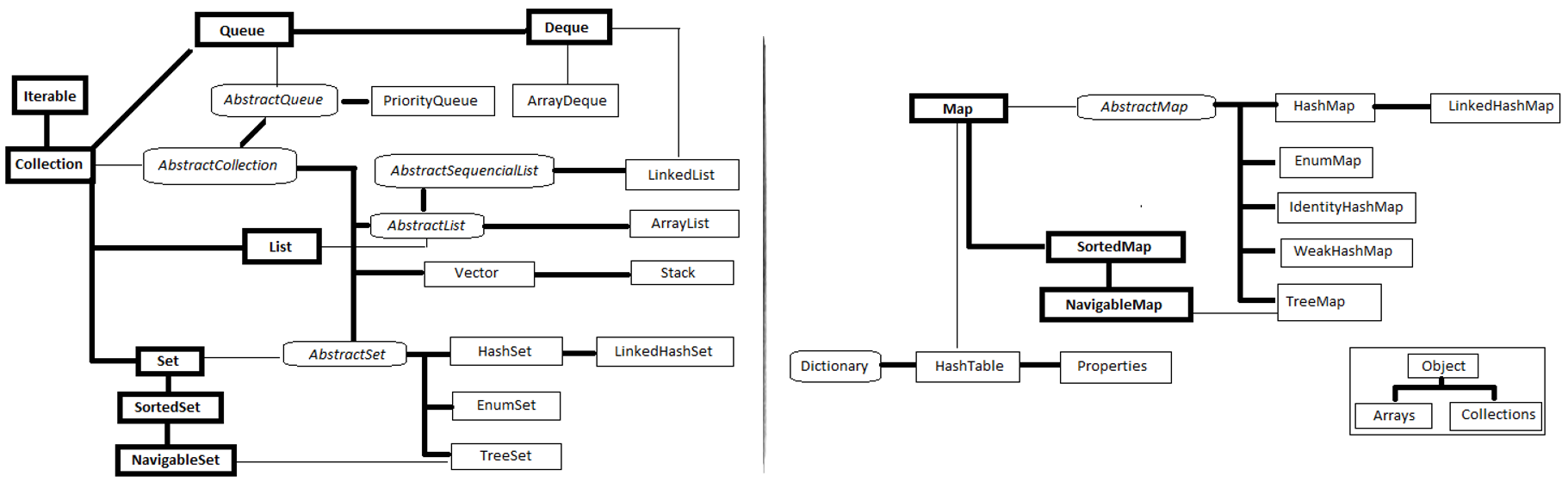
Collection Interface
- Collection extends the Iterable interface hence can be cycled through using foreach style for loop.
- Collections can be modifiable and unmodifiable, based on optional methods to do modification. Built-in collections are modifiable.
- Collections are made up of
(collection interfaces) + (Comparator, RandomAccess, Iterator, ListIterator and Spliterator interfaces).
| ClassCastException | |
| UnsupportedOperationException | |
| NullPointerException | attempt is made to store a null object and null elements are not allowed in the collection. |
| IllegalArgumentException | thrown if an invalid argument is used. |
| IllegalStateException | When attempt is made to add an element to a fixed-length collection that is full. |
Methods
| collection operations | |
|---|---|
| boolean add(E obj) | boolean addAll(Collection<? extends E> c) |
| boolean remove(Object obj) | boolean removeAll(Collection<?> c) |
| default boolean removeIf(Predicate<? super E> predicate) | |
| boolean contains(Object obj) | boolean containsAll(Collection<?> c) |
| int size( ) | boolean isEmpty( ) |
| void clear( ) | boolean retainAll(Collection<?> c) |
| boolean equals(Object obj) | int hashCode( ) |
| Iterator | default Spliterator |
| Object[ ] toArray() | ArrayStoreException, if any collection element has a type that is not a subtype of array. |
| default Stream | default Stream |
- stream() and parallelStream() - return a Stream that uses the collection as a source of elements.
List Interface
- Duplicate elements are allowed.
- zero-based index.
- You can modify each element by using replaceAll(). (UnaryOperator is a functional interface added by JDK 8.)
Collections.replaceAll(a1, "saran", "SARANYA");
- As a general rule, the collection classes are not synchronized, but it is possible to obtain synchronized versions.
- Several legacy classes, such as Vector, Stack, and Hashtable, have been re-engineered to support collections.
- RandomAccess interface contains no members, tells about support to efficient random access to its elements.
- Although a collection might support random access, it might not do so efficiently.
- Random Access classes - ArrayList, HashMap, TreeMap, Hashtable
Methods
| List Interface Methods | |
|---|---|
| void add(int index, E obj) | |
| boolean addAll(int index, Collection<? extends E> c) | |
| E remove(int index) | |
| default void replaceAll(UnaryOperator<E> opToApply) | |
| E get(int index) | |
| E set(int index, E obj) | |
| int indexOf(Object obj) – default -1 | |
| int lastIndexOf(Object obj) | |
| ListIterator<E> listIterator( ) | |
| ListIterator<E> listIterator(int index) | |
| default void sort(Comparator<? super E>comp) | |
| List<E> subList(int start, int end) – till end-1 |
ArrayList class
- ArrayList - dynamic array, increase or decrease in size.
- Dynamic arrays are also supported by the legacy class Vector
- Capacity: Size of arrayList, number elements it can hold.
- ensureCapacity() - Because reallocations are costly in terms of time, preventing unnecessary ones improves performance.
ArrayList( )
ArrayList(Collection<? extends E> c)
ArrayList(int capacity)
Why does ArrayList use transient storage?
private transient Object[] elementData; // backing array declaration
- ArrayList class can be serialized, but by design writeObject() does not save the backing array.
- Instead, it serializes the elements (including null values) till size() limit.
- This avoids the overheads of serializing the unused slots at the end of the array.
- On deserialization, a new backing array of the minimum required size is created by readObject().
Array vs ArrayList
| Array | ArrayList |
|---|---|
| Fixed size | resizable |
| primitives | Objects |
| for, for each | Iterator , for each |
| .length | size() |
| Faster O(1) | Slow in comparision |
| Multidimensional | No |
| Assignment operator | add method |
- ArrayList provides features like addAll, removeAll, iterator etc.
- ArrayList is internally backed by array hence almost same performance for add or get operation.
- During resizing as it calls the native implemented method
System.arrayCopy(src, srcPos, dest, destPos, length). - Worst case – array is full, for addition copy the data to new array of double size, might not find continuos memory locations.
- In array, ArrayStoreException, if try to store incompatible data type.
String[] arrayobj = new String[3];
String temp[] = new String[2]; // creates a string array of size 2
temp[0] = new Integer(12); // throws ArrayStoreException, trying to add Integer object in String[]
Similarities between Array and ArrayList
- Allows Duplicate
- Allows null
- Insertion order
- Same performance for add/get.
When to Use Array over ArrayList
- size of list is fixed, mostly used to store and traverse them.
- primitive data types (ArrayList slower due to auboxing and auto-unboxing).
- fixed multi-dimensional situation, using [ ][ ] is far more easier than
List<List<>>.
ArrayList vs LinkedList
| ArrayList | LinkedList |
|---|---|
| Resizable Array | Douby-LinkedList |
| ReverseIterator | |
| Initial capacity 10 | Constructs empty list |
| Fast get, Random Access | Slower (traverses completly) |
| Access - O(1) | Access - O(n) |
| Add – O(n), full array | Add – O(n) |
| Slow in comparision | Fast add |
| No Memory Overhead | Memory overhead (Node structure) |
| ArrayList | LinkedList | |
|---|---|---|
| Get | O(1) | O(n) |
| Add | O(1) | O(1) |
| Remove | O(n) | O(n) |
Similarities between ArrayList and LinkedList
- Not Synchronized
- clone(shallow copy)
- insertion order
- fail-fast iterator.
When to Use ArrayList and LinkedList
- more frequently use ArrayList than LinkedList.
- ArrayList - more get(int) or search operations, O(1).
- LinkedList - more insert(int), delete(int) than get(int).
ArrayList vs Vector
| ArrayList | Vector | |
|---|---|---|
| legacy, Synchronized, Thread-Safe | ||
| Fast | Slow (due to synchronize overhead) | |
| 50% increase | 100% | |
| Set Increment Size - No | public synchronized void setSize(int i) | |
| Iterator | Enumerator | |
| Default size - 10 |
Similarities ArrayList and Vector
- index based
- backed up by an array internally
- insertion order
- allow nulls
CopyOnWriteArrayList
- Thread safe version (concurrrent collection)
LinkedList Class
- extends AbstractSequentialList and implements List, Deque, and Queue interfaces.
- Because LinkedList implements the Deque interface, you have access to the methods defined by Deque.
- addFirst( ) or offerFirst( )
- addLast( ) or offerLast( )
- getFirst( ) or peekFirst( )
- getLast( ) or peekLast( )
- removeFirst( ) or pollFirst( )
- removeLast( ) or pollLast( )
Set Interface
- Does not allow duplicate elements.
- add( ) - returns false if attempt to add duplicate elements to a set.
| SortedSet Interface | ||
|---|---|---|
| E first( ) | ||
| E last( ) | ||
| Comparator<? super E> comparator( ) | ||
| SortedSet<E> headSet(E end) | for < end | |
| SortedSet<E> tailSet(E start) | for >= start | |
| SortedSet<E> subSet(E start, E end) | till end-1 |
| NavigableSet Interface | |
|---|---|
| Iterator | |
| NavigableSet | |
| E ceiling(E obj) | smallest element e >= obj |
| E floor(E obj) | largest element e <= obj. |
| E lower(E obj) | largest element e < obj. |
| E higher(E obj) | smallest element e > obj. |
| E pollFirst( ) | null (if empty) |
| E pollLast( ) | |
| headSet(E upperBound, boolean incl) | < upper |
| tailSet(E lowerBound, boolean incl) | > lower |
| subSet(E lower, boolean lowIncl,E upper, boolean highIncl) |
HashSet vs TreeSet vs LinkedHashSet
| HashSet | LinkedHashSet | TreeSet | |
|---|---|---|---|
| Ordering | Random | Insert Order | Sorted |
| Null Key | One | One | No |
| Null Value | Any | Any | No |
| Performance | O(1) | O(n) | O(Log(n)) |
| implementation | Hashmap | Hashmap | NavigableTreeMap |
| Comparision | equals() | equals() | compareTo() |
| Algorithm | Red-Black tree |
public TreeSet(Comparator c)
comparator.comparemethod is preferred overComparable.compareTo()
Similarities between HashSet and TreeSet
- unique elements
- shallow clone
- not thread safe
- fail-fast iterators
When to prefer TreeSet over HashSet?
- Sorted unique elements are required instead of unique elements.
- Default - ascending order
- When one need to perform read/write operations frequently
- TreeSet has greater locality than HashSet.
- In case data needs to be read from hard drive than prefer TreeSet as it has greater locality than HashSet.
HashSet class
- Collection using a hash table for storage, via hashing.
- key hashcode decides index at which the data associated with the key is stored.
- With hashing, execution time of add( ), contains( ), remove( ), and size( ) remain constant even for large sets.
- Does not guarantee the order of its elements.
- For Sorted - TreeSet.
HashSet()
HashSet(Collection<? extends E> c)
HashSet(int capacity)
HashSet(int capacity, float fillRatio)
Fill Ratio
- Range = 0.0 to 1.0, defines the point where hashset needs to be resized upward.
- Resize when
element count > (capacity x fill ratio). - Default Value = 0.75
HashSet Internal Working (How Set Ensures Uniqueness)
- HashMap is used internally.
- Key/value pair where value is always null. <3,null>
- Duplicate - add() return false and doesn’t add to HashSet.
- put (key,value) in the internal code will return
- null, if key is unique and added to the map
- Old Value of the key, if key is duplicate
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable{
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() { map = new HashMap<>(); }
// SOME CODE ,i.e Other methods in Hash Set
public boolean add(E e) { return map.put(e, PRESENT)==null; }
// SOME CODE ,i.e Other methods in Hash Set
}
LinkedHashSet Class
- LinkedHashSet maintains a linked list of the entries in the set to allow insertion-order iteration over the set.
TreeSet Class
- Creates a collection that uses a tree for storage.
- Objects are stored in sorted, ascending order.
- Access and retrieval times are quite fast, good choice when storing large sorted information that must be found quickly.
TreeSet()
TreeSet(SortedSet<E> ss)
TreeSet(Collection<? extends E> c)
TreeSet(Comparator<? super E> comp)
EnumSet Class
- For use with elements of an enum type from a single enum
- EnumSet defines no constructors, but uses factory methods.
- of() - overloaded many times. known arguments count is faster than varargs.
- Not synchronized
- Null not allowed - can throw NullPointerException.
- Fail-safe iterator, never throws ConcurrentModificationException and is weakly consistent.
class EnumSet<E extends Enum<E>>
static <E extends Enum<E>> EnumSet<E>
| EnumSet Methods | |
|---|---|
| allOf(Class<E> t) | |
| complementOf(EnumSet<E> e) | |
| of(E v) | |
| of(E v1, E v2) | |
| of(E v1, E v2, E v3) | |
| of(E v1, E v2, E v3, E v4) | |
| of(E v1, E v2, E v3, E v4,E v5) | |
| of(E v, E … varargs) | |
| copyOf(Collection<E> c) | |
| copyOf(EnumSet<E> c) | IllegalArgumentException |
| noneOf(Class<E> t) | |
| range(E start, E end) | IllegalArgumentException |
Advantage over HashSet
- constant time execution for all basic operations.
- Much faster than HashSet counterparts as hashcode can be cached.
Why Hashcode 31?
- The number 31 was chosen because it is a prime number.
- They could have chosen any other prime number.
- Hash-based collections store elements in so-called buckets. A hash-based collection has a fixed number of buckets.
- For hash-based collection, hash code of the object determines the bucket to put the object.
- bucketIndex = hashCode() % numberOfBuckets.
- When you want to find an object in a hash-based collection, this is what happens:
- Compute hashCode() of the object to find the bucket for search.
- Check all objects in the bucket by equals().
- Weak Point: Works well if elements are evenly-distributed among the buckets.
- should have a proper hashCode() method.
- HashSet and HashMap in Java have a number of buckets that is normally a power of 2 (by default, a HashMap has 16 buckets, for example).
- By making the hash code of objects a prime number (or a multiple of a prime number) the objects will be distributed better over the buckets, because a prime number is not a multiple of the number of buckets (which is a power of 2), so hashCode() % numberOfBuckets won’t quickly cycle back to the same bucket.
Queue Interface
- first-in, first-out list. (FIFO)
- Elements can only be removed from the head of the queue.
| boolean offer(E obj) | add obj to queue, true or false. (For fixed length queue, it can be false) |
| E peek( ) | return head. Null for empty |
| E poll( ) | remove and return head. Null for empty |
| E element( ) | return head. NoSuchElementException for empty |
| E remove( ) | remove and return head. NoSuchElementException for empty |
What is the difference between peek(),poll() and remove() method of the Queue interface?
- poll() - remove head object of the Queue. If Queue is empty, return null.
- remove() - remove head object of the Queue. If Queue is empty throw NoSuchElementException.
- peek() - retrieves but does not remove the head of the Queue. If queue is empty then peek() method also returns null.
PriorityQueue Class
- Creates a queue that is prioritized based on the queue’s comparator.
- PriorityQueues are dynamic, growing as necessary.
- An unbounded queue based on a priority heap.
- Elements are ordered in their natural order or provided Comparator.
- Null not allowed.
- Must be comparable or otherwise comparator is required.
- Not thread-safe and provided O(log(n)) time for enqueing and dequeing operations.
| Constructors | ||
|---|---|---|
| PriorityQueue( ) | PriorityQueue(int capacity) | |
| PriorityQueue(Collection<? extends E> c) | PriorityQueue(PriorityQueue<? extends E> c) | PriorityQueue(SortedSet<? extends E> c) |
| PriorityQueue(Comparator<? super E> comp) | PriorityQueue(int capacity, Comparator<? super E> comp) |
- default comparator - ascending order. head is smallest value.
- Comparator<? super E> comparator() - returns the comparator, null for natural ordering.
- You can iterate through a PriorityQueue using an iterator, the order of that iteration is undefined.
- To properly use PriorityQueue, call methods offer(), poll( ) defined by the Queue interface.
Deque Interface
- a double-ended queue.
- can function as standard FIFO queues or as LIFO stacks.
Methods
| Deque Interface | |
|---|---|
| void addFirst(E obj) | IllegalStateException, if queue full |
| void addLast(E obj) | IllegalStateException, if queue full |
| boolean offerFirst(E obj) | |
| boolean offerLast(E obj) | |
| E getFirst( ) | not removed, NoSuchElementException if empty |
| E getLast( ) | not removed, NoSuchElementException if empty |
| E peekFirst( ) | head, not removed. null if empty. |
| E peekLast( ) | tail, not removed. null if empty. |
| E pollFirst( ) | head, removed. null if empty. |
| E pollLast( ) | tail, removed. null if empty. |
| void push(E obj) | adds head, IllegalStateException if full. |
| E pop( ) | head, removed. NoSuchElementException if empty. |
| E removeFirst( ) | head, removed. NoSuchElementException |
| E removeLast( ) | tail, removed. NoSuchElementException |
| Boolean removeFirstOccurrence(Object obj) | |
| Boolean removeLastOccurrence(Object obj) | |
| Iterator |
ArrayDeque Class
- ArrayDeque creates a dynamic array and has no capacity restrictions.
- Deque interface supports implementations with capacity restriction.
- Default capacity is 16.
ArrayDeque()
ArrayDeque(int size)
ArrayDeque(Collection<? extends E> c)
Iterator
- Iterator - to cycle through a collection, obtaining or removing elements.
- ListIterator - allow bidirectional traversal of a List, and the modification of elements.
- remove() - UnsupportedOperationException when used with a read-only collection.
- Java8, can use Spliterator to cycle through a collection. It works differently than does Iterator.
What is an Iterator?
- Iterator interface - provides methods to iterate over any Collection, implements Iterator Design Pattern.
- iterator() method.
- allows removal during the iteration, doesn’t throw ConcurrentModificationException.
Why there is not method like iterator.add() to add elements to the collection?
- Iterator makes no guarantees about the order of iteration.
- ListIterator provide add(), as it guarantees the order of iteration.
Why Iterator don’t have a method to get next element directly without moving the cursor?
- It can be implemented on top of current Iterator interface but since it’s use will be rare; it doesn’t make sense to include it in the interface that everyone has to implement.
Why there are no concrete implementations of Iterator interface?
- Iterator interface declares methods for iterating a collection.
- implementation is responsibility of the Collection implementation classes.
- Every collection class has its own Iterator implementation nested class.
- Collection classes decide whether iterator is fail-fast or fail-safe.
For-Each Alternative to Iterators
- not modifying while iterating, or reverse order.
- forward direction for any Iterable collection.
List<String> strList = new ArrayList<>();
for(String obj : strList) //using for-each loop
System.out.println(obj);
Iterator<String> it = strList.iterator();
while(it.hasNext()){
String obj = it.next();
System.out.println(obj);
}
ListIterator<String> litr = al.listIterator();
while(litr. hasPrevious()) {
String element = litr.previous();
litr.set(element + "+");
}
Why not use for loop for Collections
For loop
- int i = 0 is an assignment and creation (2 operations)
- i get size, check value of i, and compare (3 operations)
- i++ gets i then adds 1 to it [++i is only 2 operations] this one (3 operations)
- *7/8 operations in total, each time the loop runs through
Iterator/Enumeration
- while(){} :
- while(v.hasNext()) hasNext true or false (1 operation)
- while(v.hasMoreElements()) hasMore true or false (1 operation)
- Only one operation per repeat of this loop
Iterator Methods
| Methods for Iterator | |
|---|---|
| boolean hasNext( ) | |
| E next( ) | NoSuchElementException |
| default void remove( ) | IllegalStateException |
| default void forEachRemaining(Consumer<? super E> action) |
ListIterator Methods
| Methods for ListIterator | |
|---|---|
| boolean hasNext( ) | |
| E next( ) | |
| boolean hasPrevious( ) | |
| E previous( ) | |
| int nextIndex( ) | No next element, return size |
| int previousIndex( ) | No prev, return -1 |
| void add(E obj) | |
| void remove( ) | IllegalStateException, next()/previous() req |
| void set(E obj) | IllegalStateException, next()/previous() req |
| default void forEachRemaining (Consumer<? super E> action) |
Iterator vs ListIterator
| Iterator | ListIterator |
|---|---|
| any collection | for Lists only |
| forward | bi-directional |
| next() | Previous() |
Iterator vs Enumeration
| Iterator | Enumerator |
|---|---|
| has remove() method | |
| Fail-Fast | Fail-Safe |
| throws ConcurrentModificationException if a Collection is modified while iterating other than its own remove() method | doesn’t throw ConcurrentModificationException if Collection is modified during the traversal. |
| New Interface | Legacy Interface |
| ArrayList, LinkedList, HashSet, LinkedHashSet, TreeSet, HashMap, LinkedHashMap, TreeMap etc. | Vector, HashTable and Stack |
| hasNext(), next(), remove() | hasMoreElements(), nextElement() |
| twice as fast as Iterator | |
| uses very less memory |
Fail-Fast vs Fail-Safe Iterators
- Iterator fail-fast property checks for any modification in the structure of the underlying collection everytime we try to get the next element. If there are any modifications found, it throws ConcurrentModificationException.
| Fail-Fast | Fail-Safe | |
|---|---|---|
| package | java.util | java.util.concurrent |
| throws | ConcurrentModificationException | |
| Works with | Original collection | Clone of underlying collection |
| collection | By default all collections are fail-fast (ArrayList) | ConcurrentHashMap, CopyOnWriteArrayList |
What is UnsupportedOperationException?
java.util.Collections.UnmodifiableCollectionthrows this exception for all add and remove operations.
Fail fast Iterator
Scenarios for ConcurrentModificationException
- Single Threaded Environment - After iterator creation, structure modified by other iterator’s own remove method.
- Multiple Threaded Environments - one thread is iterating and other is modifying the structure.
Is Fail Fast behaviour Guaranteed?
- According to Oracle docs , the fail-fast behavior of an iterator cannot be guaranteed as its impossible to make any concrete guarantees in the presence of unsynchronized concurrent modification.
- Fail-fast iterators throw ConcurrentModificationException on a best-effort basis.
- Fail-fast behavior of iterators should be used only to detect bugs.
How Fail Fast Iterator come to know that the internal structure is modified?
- Collections maintain an internal flag mods.
- “mods” flag checked before every hasNext() and next().
- On any structural modification, mods flag changes, thus indicating iterator to throw ConcurrentModificationException.
Fail Safe Iterator
- Makes copy of the internal data structure (object array) and iterates over the copied data structure.
- Any structural modification doesn’t affect iterator hence, no ConcurrentModificationException.
Two issues associated with Fail Safe Iterator are
- Overhead of maintaining the copied data structure i.e memory.
- No guarantee that data being read is the data currently in the original data structure.
ConcurrentHashMap<String, String> map = new ConcurrentHashMap< >();
Iterator iterator = map.keySet().iterator();
- Oracle docs , fail safe iterator is ordinarily too costly, efficient when traversal operations vastly outnumber mutations.
- “snapshot” style iterator method uses a reference to the state of the array at the point that the iterator was created.
- This array never changes during the lifetime of the iterator, so interference is impossible and the iterator is guaranteed not to throw ConcurrentModificationException.
- The iterator will not reflect additions, removals, or changes to the list since the iterator was created.
- Mutating operations remove(), set(),add() are not supported on iterators. (UnsupportedOperationException)
Spliterators
- supports parallel programming, ability to parallel iteration of portions of the sequence.
- combines hasNext and next into one method
tryAdvance(), streamlined approach.
Basic iteration task is quite easy:
- tryAdvance( ) until it returns false.
- For tryAdvance( ), each iteration passes next element to objRef. Often, implementing Consumer by lambda is easiest way.
- forEachRemaining(), streamlined alternative, Consumer defines action.
Spliterator
- most useful for parallel processing.
- attributes, called characteristics are static int.
- example - SORTED, DISTINCT, SIZED, and IMMUTABLE, etc.
- Spliterator.OfPrimitive(), Spliterator.OfDouble, Spliterator.OfInt, and Spliterator.OfLong.
ArrayList<Double> vals;
Spliterator<Double> spltitr = vals.spliterator();
while(spltitr.tryAdvance((n) -> System.out.println(n)));
System.out.println();
spltitr = vals.spliterator();
ArrayList<Double> sqrs = new ArrayList<>();
while(spltitr.tryAdvance((n) -> sqrs.add(Math.sqrt(n))));
System.out.print("Contents of sqrs:\n");
spltitr = sqrs.spliterator();
spltitr.forEachRemaining((n) -> System.out.println(n));
// Contents of vals:
1.0
2.0
3.0
4.0
5.0
// Contents of sqrs:
1.0
1.4142135623730951
1.7320508075688772
2.0
2.23606797749979
Methods
| Spliterator | |
|---|---|
| boolean tryAdvance (Consumer<? super T> action) | false if no element left |
| Spliterator<T> trySplit( ) | |
| default Boolean hasCharacteristics(int val) | |
| int characteristics( ) | |
| long estimateSize( ) | elements left to iterate, else Long.MAX_VALUE |
| default long getExactSizeIfKnown( ) | -1 |
| default void forEachRemaining(Consumer<? super T> action) | |
| default Comparator<? super T> getComparator( ) | null for natural ordering |
- trySplit() - original spliterator iterates one portion, while returned spliterator iterates other portion.
Map Interface
- Map – stores data as key/value pairs.
- Map<K, V>
- K specifies the type of keys
- V specifies the type of values.
- Some maps can accept a null key and null values, others cannot.
- not Iterable, can’t obtain iterator to a map.
| Map | Maps unique keys to values. |
| Map.Entry | inner class of Map. Defines element as key-value pair. |
| SortedMap | keys are maintained in ascending order |
| NavigableMap | Extends SortedMap to handle the retrieval of entries based on closest-match searches. |
Why Map interface doesn’t extend Collection interface?
- Map doesn’t fit into the “group of elements” paradigm.
- Map contains key-value pairs and it provides methods to retrieve list of Keys or values as Collection.
- By getting a collection-view, maps are integrated into the larger Collections Framework.
- entrySet( ) - returns a Set that contains the elements in the map.
- keySet( ) - To obtain a collection-view of the keys.
- values( ) - To get a collection-view of the values.
Methods
| int size( ) | |
| boolean isEmpty( ) | |
| void clear( ) | |
| int hashCode( ) | |
| boolean equals(Object obj) | |
| Set< Map.Entry<K, V> > entrySet( ) | |
| Set<K> keySet( ) | |
| Collection<V> values( ) | |
| boolean containsKey(Object k) | |
| boolean containsValue(Object v) | |
| V get(Object k) | |
| default V getOrDefault(Object k, V defVal) | |
| V put(K k, V v) | |
| default V putIfAbsent( K k, V v) | |
| void putAll(Map<? extends K, ? extends V> m) | |
| V remove(Object k) | |
| default boolean remove(Object k, Object v) | |
| default V replace(K k, V v) | |
| default boolean replace(K k, V oldV, V newV) | |
| default void replaceAll(BiFunction< ? super K, ? super V, ? extends V> func) | |
| forEach(BiConsumer<? super K,? super V> action) | ConcurrentModificationException |
| default V merge(K k, V v, BiFunction<? super V, ? super V, ? extends V> func) |
SortedMap Interface
- Ascending order on keys.
- firstKey( ) – smallest.
- lastKey() - largest.
- Several methods throw a NoSuchElementException when no items are in the invoking map.
- efficient manipulations of submaps. headMap( ), tailMap( ), subMap( ).
- The submap returned by these methods is backed by the invoking map ie. Changing one changes the other.
NavigableMap Interface
- The NavigableMap interface extends SortedMap
- supports retrieval of entries based on the closest match to a given key or keys.
- ClassCastException (incompatible), NullPointerException (not Nullable), IllegalArgumentException (invalid argument).
Methods
| NavigableMap Interface | |
|---|---|
| Map.Entry<K,V> firstEntry( ) | |
| Map.Entry<K,V> lastEntry( ) | |
| K firstKey( ) | |
| K lastKey( ) | |
| SortedMap<K, V> tailMap(K start) | |
| SortedMap<K, V> headMap(K end) | |
| SortedMap<K, V> subMap(K start, K end) | |
| NavigableMap<K,V> headMap(K upper, boolean incl) | |
| NavigableMap<K,V> tailMap(K lowerBound, boolean incl) | |
| NavigableMap<K,V> subMap(K lower, boolean lowIncl, K upper, boolean highIncl) | |
| Comparator<? super K> comparator( ) | |
| Map.Entry<K,V> ceilingEntry(K obj) | smallest k >= obj |
| K ceilingKey(K obj) | smallest k >= obj |
| Map.Entry<K,V> floorEntry(K obj) | largest k <= obj. |
| K floorKey(K obj) | largest k <= obj. |
| Map.Entry<K,V> higherEntry(K obj) | smallest k > obj |
| K higherKey(K obj) | smallest k > obj |
| Map.Entry<K,V> lowerEntry(K obj) | largest k < obj |
| K lowerKey(K obj) | largest k < obj. |
| NavigableMap<K,V> descendingMap( ) | |
| NavigableSet | |
| NavigableSet | |
| Map.Entry<K,V> pollFirstEntry( ) | |
| Map.Entry<K,V> pollLastEntry( ) |
Map.Entry Interface
- entrySet() - returns a Set containing the map entries. (Map.Entry)
- comparingByKey(), which returns a Comparator that compares entries by key.
- comparingByValue(), which returns a Comparator that compares entries by value.
int hashCode( )
K getKey( )
V getValue( )
boolean equals(Object obj)
V setValue(V v)
- ClassCastException (incompatible),
- IllegalArgumentException,
- NullPointerException (not nullable),
- UnsupportedOperationException (unmodifiable)
Map Classes
| Class | Description |
|---|---|
| AbstractMap | Implements most of the Map interface. |
| HashMap | Extends AbstractMap to use a hash table. |
| LinkedHashMap | Extends HashMap to allow insertion-order iterations. |
| TreeMap | Extends AbstractMap to use a tree. |
| EnumMap | Extends AbstractMap for use with enum keys. |
| WeakHashMap | Extends AbstractMap to use a hash table with weak keys. |
| IdentityHashMap | Extends AbstractMap and uses reference equality when comparing documents. |
Arrange the following in the ascending order (performance)?
Hashtable < Collections.SynchronizedMap < ConcurrentHashMap < HashMap
hashcode() and equals()
hashCode() and equals() methods, what is their contract?
- hashCode() and equals() of key object is critical.
- Implementation of equals() and hashCode() should follow these rules:
o1.equals(o2)true =>o1.hashCode() == o2.hashCode()always true.o1.hashCode() == o2.hashCode()true => not necessary thato1.equals(o2)is true.
What are use-cases of hashcode() and equals()?
- HashMap – uses hashcode() of Key object to determine index of segment where key-value pair is to be put.
- HashMap – uses hashcode() to find lookup segement index, then equals() to get value from linked list in segment.
- Collection classes that doesn’t allow duplicates uses hashCode() and equals() to find duplicates. Ex- HashSet.
Can we use any class as Map key?
- Only if hashCode and equals contract is maintainted.
- If class overrides equals(), should override hashCode() too.
- Only those fields used in equals() should be used in hashCode().
- Best practice - user defined key class to be made immutable, so that hashCode() value can be cached for fast performance.
- Immutable classes makes sure that hashCode() and equals() will not change in future as well.
What is problem if hashcode and equals not correctly implemented?
two different Key’s might produce same hashCode() and equals(), causing faulty overwriting of element in HashMap.
Why have immutable objects as keys? Or Where do we need immutable Objects?
- Due to possibility of below case, immutable classes are used as keys such as String, Integer etc.
MyKey key = new MyKey("Pankaj"); // assume hashCode=1234
myHashMap.put(key, "Value");
key.setName("Amit"); // assume new hashCode=7890
myHashMap.get(new MyKey("Pankaj")); // not found
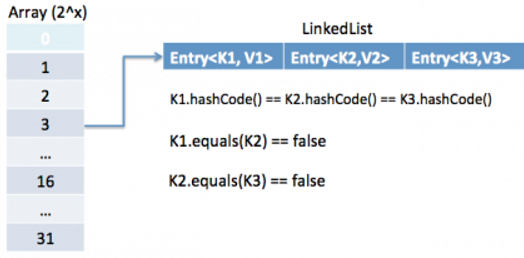
What is hash-collision in Hashtable ? How it was handled in Java?
- In Hashtable, if two different keys have the same hash value then it leads to hash-collision.
- A bucket of type linkedlist used to hold the different keys of same hash value.
Maps Summarized
| Property | HashMap | TreeMap | LinkedHashMap | HashTable |
|---|---|---|---|---|
| Insertion Order | Random | Sorted (Natural Order) | Sorted (Insertion Order) | Random |
| Performance | O(1) | O(log(n)) | O(1) | O(1) |
| Null Keys | Yes | No | Yes | No |
| Null Values | Yes | No | Yes | No |
| Interfaces | Map | Map, SortedMap, NavigableMap | Map | Map |
| Synchronized | No, Collections.synchronizedMap(new HashMap()) | Yes | ||
| Implementation Algorithm | Buckets | Red-Black Tree | HashTable and LinkedList using doubly linked list of Buckets | Buckets |
| Comments | Efficient | Extra Cost of Maintaining TreeMap | TreeMap Advantages, no extra cost | Obselete |
HashMap
- It uses a hash table to store the map. This allows the execution time of get( ) and put( ) to remain constant even for large sets.
- The default capacity is 16.
- The default fill ratio is 0.75.
- A hash map does not guarantee the order of its elements.
- The put( ) method automatically replaces any pre-existing value that is associated with the specified key with the new value.
HashMap( )
HashMap(Map<? extends K, ? extends V> m)
HashMap(int capacity)
HashMap(int capacity, float fillRatio)
What are different Collection views provided by Map interface?
Set<K> keySet(): Set view of the keys contained in this mapCollection<V> values(): Collection view of the values contained in this map-
Set<Map.Entry<K, V>> entrySet(): Set view of the mappings contained in this map - set/collection is backed by the map, so changes to the map are reflected in the set, and vice-versa.
- If map modified while iteration over the set is in progress (except via iterator’s methods), results of iteration are undefined.
- The set supports element removal, mapping removed from map, via
- Iterator - remove,
- Set - remove, removeAll, retainAll, clear operations.
- It does not support the add or addAll operations.
Internal Working
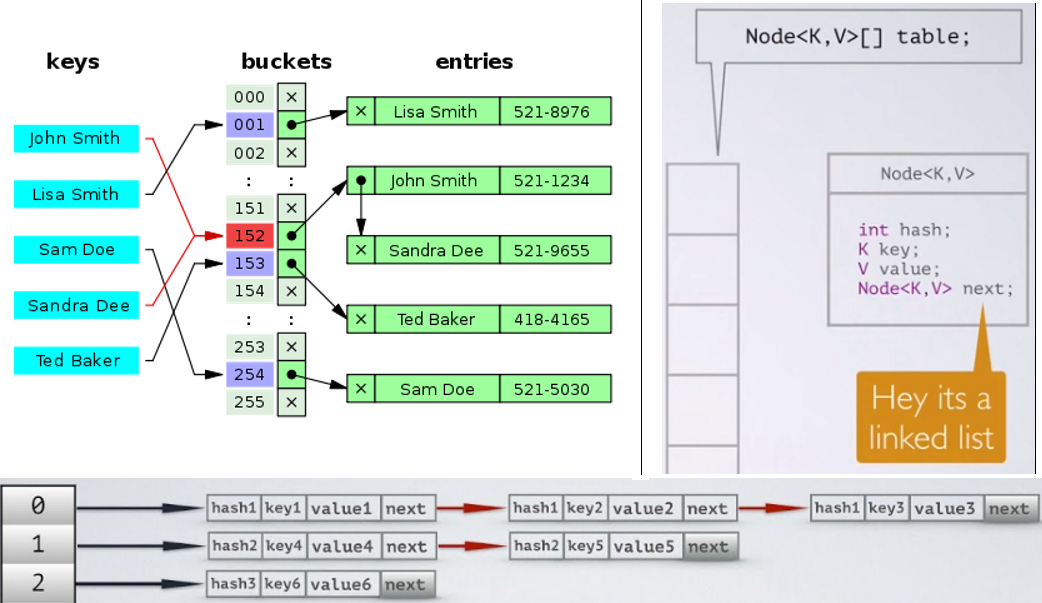
Bucket
- A bucket/segment is used to store key value pairs.
- A bucket can have multiple key-value pairs.
- In hash map, bucket uses simple linked list to store objects.
- It is not a LinkedList as in a
java.util.LinkedList- It’s a separate (simpler) implementation just for the map.
get(Key k)
- key is null, then hash and index both are 0.
- key not null, key.hashCode() passed to static hash function to find a bucket location(backing array) ie. index.
- both key and value is stored in the bucket as a form of Entry object.
- Entry object stores in the bucket like this (hashcode, key, value, next).
- traverse through linked list, keys.equals() until it return true. Return value of corresponding entry object.
Public V get(Object key) {
if (key ==null)
// Some code
int hash = hash(key.hashCode());
// if key found in hash table then return value
// else return null
}
Why calculate hashvalue again using hash(hashValue)
- hashCode gives an int that may be out index range, do modulo hashing.
put()
When an element is added / retrieved, same procedure follows:
- Using key.hashCode(), determine initial hashvalue for the key.
- Pass intial hashvalue as hashValue in hash(hashValue) function, to calculate the final hashvalue.
- Final hash value is then passed as a first parameter in the indexFor(int ,int) method. The second parameter is length which is a constant in HashMap Java Api, represented by DEFAULT_INITIAL_CAPACITY(default 16).
- indexFor(int,int) method returns the first entry in the appropriate bucket.
- The linked list in the bucket is then iterated over - (the end is found and the element is added or the key is matched and the value is returned)
/*Returns index for hash code h.*/
static int indexFor(int h, int length) { return h & (length-1); }
- The above function indexFor() works because Java HashMaps always have a capacity, i.e. number of buckets, as a power of 2.
Example
- capacity 256, 0x100, but it could work with any power of 2.
- Subtracting 1 from a power of 2 yields the exact bit mask needed to bitwise-and with the hash to get the proper bucket index, of range 0 to length - 1.
256 - 1 = 255
0x100 - 0x1 = 0xFF
E.g. a hash of 257 (0x101) gets bitwise-anded with 0xFF to yield a bucket number of 1.
How will you measure the performance of HashMap?
- capacity - default 16
- load factor - default 0.75
number of entries > (load factor) x (current capacity), hash table is rehashed to have twice the number of buckets.
time complexity of Hashmap get() and put() – due to hashing O(1), buckets have specified.
How do you use a custom object as key in Collection classes like HashMap?
- Override equals() and hashCode() method to fulfill the contract.
- If not implemented correctly, it will result in two keys producing the same hashCode() and equals() output.
- This causes unexpected overwrite of key-value pair.
- For SortedCollections (SortedMap), make sure that equals() is consistent to compareTo().
- If inconsistent, then collection will not follow their contracts, that is, Sets may allow duplicate elements.
HashMap Improvement in Java 8
- when a bucket becomes too big (TREEIFY_THRESHOLD = 8), HashMap dynamically replaces it with an ad-hoc implementation of tree map.
- Now, rather than O(n) we get O(logn) due to Tree data structure for the bucket.
- HashMap promotes list into binary tree, using hashCode() as a branching variable.
- In a bucket to be transformed to Red Black Tree,
- If two hashes are different, bigger hashcode becomes right child.
- If hashes are equal,
- HashMap hopes keys to be Comparable and establish some order. (not a requirement, but a good practice).
- If keys are not comparable, don’t expect any performance improvements in case of heavy hash collisions.
When and how does HashMap convert the bucket from linked list to Red Black Trees?
- single bucket will be transformed to a perfectly balanced red black tree node.
- single bucket has at least 8 entries (TREEIFY_THRESHOLD)
- total number of buckets is more then 64 buckets (MIN_TREEIFY_CAPACITY)
- Shrinkage happens when you remove entries, UNTREEIFY_THRESHOLD == 6
- Keys should be Comparable - but that is not always required, it is good if they are (in case they have the same hashCode), but in case they are not, below tieBreakOrder() is used:
static int tieBreakOrder(Object a, Object b) {
int d;
if (a==null || b==null || (d=a.getClass().getName().compareTo(b.getClass().getName()))==0)
d = (System.identityHashCode(a)<=System.identityHashCode(b)?-1:1);
return d;
}
So the className as a String is used for comparison and if that fails too, then System.identityHashCode is used (Marsaglia XOR-Shift algorithm) to decide the left and right.
When does this conversion happen?
- When resize of your HashMap is required, number of buckets increases by a factor of 2.
- or when a certain bucket is transformed to a tree.
This process of converting LinkedList to Red Black Tree is pretty slow
- Java HashMap is “sloooooooow, then is fast fast fast; then it’s sloooooo, then it’s fast fast fast” (There are PauselessHashMap implementations).
This brings two interesting points:
- Choose correct size of your Map initially in order to avoid some resize cycles. (new HashMap<>(256);)
- Why transforming to a Tree is important (think database indexes and why they are B-Tree…).
- How many steps it would take you to find an entry in a perfect tree that has INTEGER.MAX_VALUE entries (theoretically). Only up to 32.
remove()
- find the desired Entry object for removal - hashValue, key and bucketindex.
- remove(key) - calls removeEntryForKey(key) method internally, which calculate the final hashValue of the key object.
- hashValue is passed in the indexFor(int,int) method to find the first entry object in the appropriate bucket.
- bucket(var table) is a LinkedList effectively, start traversal from object returned by indexFor(int,int).
- if .eqauls() return true for a key during traversal, removed that single entry object from the LinkedList.
- local variable e contains the Entry returned by removeEntryForKey(key) method.
If(e==null)
return null
else
return value of removed Entry object.
time complexity remove(key)
- Best Case time complexity of remove(key) : O(1)
- Worst Case time complexity of remove(key) : O(n)
removeEntryForKey(key) has recordRemoval() concrete method without any body, what’s the use?
- empty concrete method
recordRemoval()is invoked whenever the Entry is removed from the table. - Since LinkedHashMap extends HashMap, it is overridden in LinkedHashMap’s Entry to maintain its linked list of entries.
HashMap vs HashTable
| HashMap | Hashtable | |
|---|---|---|
| Synchronized | No | Yes |
| Thread-Safe | No | Yes |
| Null Keys | One null key | No |
| Null values | Any null values | No |
| Iteration | Iterator | Enumerator |
| Iterator type | Fail fast iterator | Fail safe iterator |
| Performance | Fast | Slow in comparison |
| Superclass | AbstractMap | Dictionary |
| Legacy | No | Yes |
When to use HashMap and Hashtable?
- Unsynchronized/single threaded- Use HashMap in.
- Multithreaded - Hashtable/ConcurrentHashMap.
- Java 8, ConcurrentHashMap used rather than HashTable.
Similarities between HashMap and Hashtable
- Do not guarantee insertion order
- based on hashing
- constant time performance(put/get)
HashMap vs ConcurrentHashMap
Collections.synchronizedMap(HashMap)is equivalent to the HashTable object.- When a modification is performed, Map is locked on Map object.
- ConcurrentHashMap synchronizes or locks at segment level rather than whole Map Object.
- Optimized performance, Map is divided into different partitions depending upon the Concurrency level.
When to use TreeMap over HashMap
- when key traversal in sorted order is required.
- Based on collection size, it is faster to add elements to HashMap and then convert to a TreeMap.
LinkedHashMap
- It maintains a linked list of the entries in the map. This allows insertion-order iteration over the map.
- The default capacity is 16.
- The default fill-ratio is 0.75.
- Order flag
- true : access order is used.
- false: insertion order is used.
LinkedHashMap( )
LinkedHashMap(Map<? extends K, ? extends V> m)
LinkedHashMap(int capacity)
LinkedHashMap(int capacity, float fillRatio)
LinkedHashMap(int capacity, float fillRatio, boolean Order)
LinkedHashMap adds only one method to those defined by HashMap
- protected boolean
removeEldestEntry(Map.Entry<K, V> e) - This method is called by put( ) and putAll( ). The oldest entry is passed in e.
- By default, this method returns false and does nothing. To use it, you override this method.
- Have your override return true to remove. To keep the oldest entry, return false.
Internal Working
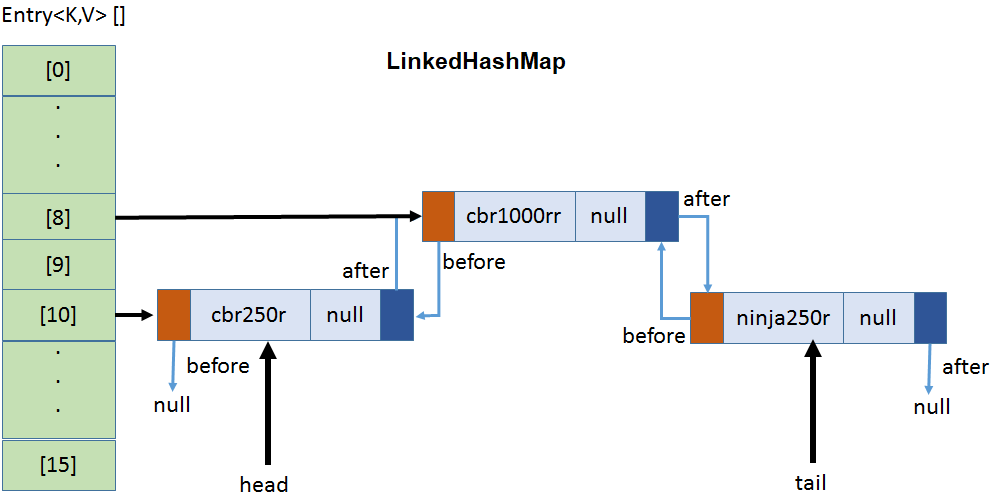
Other Maps
TreeMap
- It creates maps stored in a tree structure.
- TreeMap stores key/value pairs in sorted order with rapid retrieval.
- The fourth form initializes a tree map with the entries from sm, which will be sorted in the same order as sm.
TreeMap( )
TreeMap(Comparator<? super K> comp)
TreeMap(Map<? extends K, ? extends V> m)
TreeMap(SortedMap<K, ? extends V> sm)
- Treemap is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time, depending on which constructor is used.
- log(n) time for containsKey(), get(), put() and remove().
- Fail-Fast iterator.
- clone() - Shallow copy of the TreeMap instance
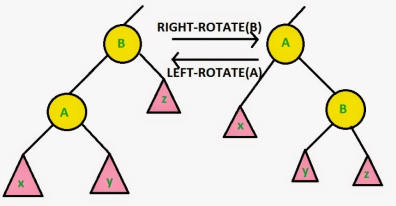
How TreeMap works in java?
- TreeMap is a Red-Black tree based NavigableMap implementation.
Properties of Red Black tree:
- As the name of the algorithm suggests, color of every node in the tree is either red or black.
- Root node must be Black in color.
- Red node can not have a red color neighbor node.
- All paths from root node to the null should consist of the same number of black nodes.
- Rotations maintains the inorder ordering of the keys(x,y,z).
- A rotation can be maintained in O(1) time.
Why Treemap does not allow an initial size while HashMap does?
- HashMap re-hashes its buckets when new one gets inserted beyond the capacity.
- TreeMap does not reallocate nodes on adding new ones.
- Hence, size of the TreeMap dynamically increases if needed, without shuffling the internals.
IdentityHashMap
- It is similar to HashMap except that it uses reference equality when comparing elements.
- The API documentation explicitly states that IdentityHashMap is not for general use.
- Uses reference equality instead of object equality when comparing keys and values.
- In IdentityHashMap two keys k1 and k2 are considered equal if only if (k1==k2).
- IdentityHashMap is not synchronized.
- fail-fast iterator, ConcurrentModificationException will be thrown.
EnumMap
EnumMap(Class<K> kType)
EnumMap(Map<K, ? extends V> m)
EnumMap(EnumMap<K, ? extends V> em)
- It is specifically for use with keys of an enum type.
- class EnumMap<K extends Enum<K>, V>
- K must extend Enum<K>, which enforces the requirement that the keys must be of an enum type.
WeakHashMap
- WeakHashMap has weak keys.
- An entry in WeakHashMap will automatically be removed when its key is no longer in ordinary use.
- Presence of a mapping for a given key will not prevent the key from being discarded by the garbage collector.
- It permits null keys and null values.
- Not synchronized, use Collections.synchronizedMap().
- fail-fast iterator, ConcurrentModificationException will be thrown.
MultivaluedMap
- public interface MultivaluedMap<K,V> extends
java.util.Map<K, java.util.List<V>> - Nested Class - java.util.Map.Entry<K,V>
- javax.ws.rs.core Interface
- A map of key-values pairs. Each key can have zero or more values.
Methods inherited from interface java.util.Map
clear, containsKey, containsValue, entrySet, equals, get, hashCode, isEmpty, keySet, put, putAll, remove, size, values
public void get(@Context UriInfo ui) {
MultivaluedMap params = ui.getRequestUri().getQuery();
// now do what you want with your params
}
Methods
| MultivaluedMap Methods | |
|---|---|
| Void add(K key, V value) | Add a value to the current list of values for the supplied key. |
| Void addAll(K key, List | |
| Void addAll(K key, V… newValues) | |
| Void addFirst(K key, V value) | Add a value to the first position in the current list of values for the supplied key. |
| Boolean equalsIgnoreValueOrder(MultivaluedMap<K,V> otherMap) | Compare the specified map with this map for equality modulo the order of values for each key. |
| V getFirst(K key) | A shortcut to get the first value of the supplied key. |
| Void putSingle(K key, V value) | Set the key’s value to be a one item list consisting of the supplied value. |
Comparator
- TreeSet, TreeMap store elements in sorted order.
- Custom definition of “sorted order” when natural-sorting is not desirable.
- interface Comparator
List of Methods : Comparator
| Methods | |
|---|---|
| int compare(T obj1, T obj2) | obj1 - obj2 |
| boolean equals(object obj) | |
| default Comparator | |
| default Comparator | cascade compare by X then by Y sequence. |
| static <T extends Comparable <? super T» Comparator | |
| static <T extends Comparable <? super T» Comparator | |
| static | |
| static |
class MyComp implements Comparator<String> {
public int compare(String aStr, String bStr){
return bStr.compareTo(aStr); // Reverse the comparison.
}
}
MyComp mc = new MyComp();
TreeSet<String> ts = new TreeSet<String>(mc.reversed()); // reverse order of MyComp
// Comparator by Lambda
Comparator<String> mc = (aStr, bStr) -> bStr.compareTo(aStr);
Comparator<Person> c = Comparator.comparingInt(Person::getAge);
// Cascaded Comparator
Comparator<Person> multiComparator = Comparator.comparing(Person::getFirstName);
multiComparator = multiComparator.thenComparing(Comparator.comparing(Person::getLastName));
Collections.sort(persons, multiComparator);
CompLastNames compLN = new CompLastNames();
Comparator<String> compLastThenFirst = compLN.thenComparing (new CompThenByFirstName());
TreeMap<String, Double> tm = new TreeMap<String, Double>(compLastThenFirst);
Collections.sort(reportList, Comparator.comparing(Report::getReportKey).thenComparing(Report::getStudentNumber).thenComparing(Report::getSchool));
Comparable vs Comparator
| Comparable | Comparator |
|---|---|
| natural ordering | Custom ordering |
| Only one sort sequence | Many sort sequences can be created on attribute. (Collections.sort()) |
| compareTo(Object o) | compare (Object o1, Object o2) |
| public boolean equals(Object obj) | |
| sgn(comp1.compare(o1, o2))==sgn(comp2.compare(o1, o2)) | |
| java.lang | java.util package |
| Need to Modify Classes – Must have source Code | No need to Modify Classes – Third Party cases |
//If this.id < country.id: return -1
//If this.id > country.id: return 1
//If this.id ==country.id: return 0
public class Country implements Comparable<Country>{
int id;
String countryName;
@Override
public int compareTo(Country country) {
return (this.id < country.id) ? -1 : (this.id > country.id ? 1 : 0) ;
}
}
Collections.sort(listOfCountries);
//If country1.id < country2.id: return -1
//If country1.id > country2.id: return 1
//If country1.id ==country2.id: return 0
public class CountryIdComparator implements Comparator<Country>{
@Override
public int compare(Country c1, Country c2) {
return (c1.getCountryId() < c2.getCountryId()) ? -1 : (c1.getCountryId() > c2.getCountryId() ? 1 : 0) ;
}
}
Collections.sort(listOfCountries , comparatorById);
Collections.sort(listOfCountries , comparatorByName);
Collections class
- Collections class - several algorithms as static methdos.
- checked methods - returns “dynamically typesafe view” of a collection, Compatibility check at run time (insertion).
- Example checkedCollection(), checkedSet( ), checkedList( ), checkedMap( ), and so on.
- synchronized (thread-safe) copies - synchronizedList(), synchronizedSet().
- General rule, standard collections implementations are not synchronized.
- One other point: iterators to synchronized collections must be used within synchronized blocks.
Add/Insert
static <T> Boolean addAll(Collection<? super T> c, T... elements)
static <T> boolean replaceAll(List<T> list, T old, T new)
static <T> void fill(List<? super T> list, T obj)
Algo - Min/Max/Frequency
static <T> T max(Collection<? extends T> c, Comparator<? super T> comp)
static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> c)
static <T> T min(Collection<? extends T> c, Comparator<? super T> comp)
static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> c)
static int frequency(Collection<?> c, object obj)
Algo - Binary Search
static <T> int binarySearch(List<? extends Comparable<? super T>> list, T value)
static <T> int binarySearch(List<? extends T> list, T value, Comparator<? super T> c)
Algo - Sort/Reverse
static <T> void sort(List<T> list, Comparator<? super T> comp)
static <T extends Comparable<? super T>> void sort(List<T> list)
static void reverse(List<T> list)
static <T> Comparator<T> reverseOrder(Comparator<T> comp) // returns reversal comparator
static <T> Comparator<T> reverseOrder( )
Checked Collection
static <E> Collection<E> checkedCollection(Collection<E> c, Class<E> t)
static <E> List<E> checkedList(List<E> c, Class<E> t)
static <E> Queue<E> checkedQueue(Queue<E> q, Class<E> t)
static <E> List<E> checkedSet(Set<E> c, Class<E> t)
static <E> NavigableSet<E> checkedNavigableSet(NavigableSet<E> ns, Class<E> t)
static <E> SortedSet<E> checkedSortedSet(SortedSet<E> c, Class<E> t)
static <K, V> Map<K, V> checkedMap(Map<K, V> c, Class<K> keyT, Class<V> valueT)
static <K, V> NavigableMap<K, V> checkedNavigableMap(NavigableMap<K, V> nm, Class<E> keyT, Class<V> valueT)
static <K, V> SortedMap<K, V> checkedSortedMap(SortedMap<K, V> c, Class<K> keyT, Class<V> valueT)
Copy
static <T> void copy(List<? super T> list1, List<? extends T> list2) // Copies the elements of list2 to list1.
Empty Collections
static <T> List<T> emptyList( )
static <T> Set<T> emptySet( )
static <E> NavigableSet<E> emptyNavigableSet( )
static <E> SortedSet<E> emptySortedSet( )
static <K, V> Map<K, V> emptyMap( )
static <K, V> NavigableMap<K, V> emptyNavigableMap( )
static <K, V> SortedMap<K, V> emptySortedMap( )
Iterate/Enumerate
static <T> Iterator<T> emptyIterator( )
static <T> ListIterator<T> emptyListIterator( )
static <T> Enumeration<T> emptyEnumeration( )
static <T> Enumeration<T> enumeration(Collection<T> c)
SubList
static int indexOfSubList(List<?> list, List<?> subList)
static int lastIndexOfSubList(List<?> list, List<?> subList)
static <T> ArrayList<T> list(Enumeration<T> enum)
Misc
static <T> Queue<T> asLifoQueue(Deque<T> c)
static <E> Set<E> newSetFromMap(Map<E, Boolean> m)
static boolean disjoint(Collection<?> a, Collection<?> b) // true, when no common elements
static <T> List<T> nCopies(int num, T obj) // Returns num copies of obj in immutable list. num >=0.
Operations – Rotate/Shuffle/Swap
static void rotate(List<T> list, int n) // Rotates list by n places to the right. -ve to left rotate.
static void shuffle(List<T> list, Random r)
static void shuffle(List<T> list)
static void swap(List<?> list, int idx1, int idx2) // Exchanges the elements in list at the indices specified by idx1 and idx2.
Singleton
static <T> Set<T> singleton(T obj)
static <T> List<T> singletonList(T obj)
static <K, V> Map<K, V> singletonMap(K k, V v)
Synchronized
static <T> Collection<T> synchronizedCollection(Collection<T> c)
static <T> List<T> synchronizedList(List<T> li)
static <T> Set<T> synchronizedSet(Set<T> s)
static <T> NavigableSet<T> synchronizedNavigableSet(NavigableSet<T> ns)
static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> ss)
static <K, V> Map<K, V> synchronizedMap(Map<K, V> m)
static <K, V> NavigableMap<K, V> synchronizedNavigableMap(NavigableMap<K, V> nm)
static <K, V> SortedMap<K, V> synchronizedSortedMap(SortedMap<K, V> sm)
Unmodifiable
static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c)
static <T> List<T> unmodifiableList(List<? extends T> list)
static <T> Set<T> unmodifiableSet(Set<? extends T> s)
static <T> NavigableSet<T> unmodifiableNavigableSet(NavigableSet<T> ns)
static <T> SortedSet<T> unmodifiableSortedSet(SortedSet<T> ss)
static <K, V> Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m)
static <K, V> NavigableMap<K, V> unmodifiableNavigableMap(NavigableMap<K, ? extends V> nm)
static <K, V> SortedMap<K, V> unmodifiableSortedMap(SortedMap<K, ? extends V> sm)
Collections defines three static variables: EMPTY_SET, EMPTY_LIST, and EMPTY_MAP. All are immutable.
| FAQ | |
|---|---|
| How to get read-only Collections? | Collections.unmodifiableCollection(Collection c), throw UnsupportedOperationException |
| How to reverse the List in Collections? | Collections.reverse(listobject) |
| How to convert the array of strings into the list? | Arrays.asList(wordArray) |
| How can we sort a list of Objects? | Arrays.sort() or Collections.sort() |
- overloaded sort() methods - natural sorting (Comparable) and custom sorting (Comparator).
- Collections.sort internally uses Arrays.sort sorting method, so they have same performance except that Collections take sometime to convert list to array.
Why java.util.Arrays uses Two Sorting Algorithms?
Read article here
| Quick sort (dual pivot quicksort) | primitive types such as int | worst case - O(n^2) |
| Merge sort | for objects that implement Comparable or use a Comparator. | worst case - O(n log n) |
- Mergesort is stable in both cases.
- Quicksort is faster in both cases. For primitive, Quicksort is stable too.
[7, 6, 6, 7, 6, 5, 4, 6, 0] // All 6 are same as they don’t hold object references.
- If using objects, maybe space is not a critical and extra space used by a merge sort maybe not be a problem.
- If using primitive, maybe performance is most important so they use quick sort.
Arrays class
- Arrays class - provides methods to bridge the gap between collections and arrays.
List from Array
static <T> List asList(T... array) // List backed by array, both the list and the array refer to the same location
static void fill(char array[ ], char value)
static void setAll(double array[ ])
static void parallelSetAll(double array[ ])
Algo - Binary Search
static int binarySearch(char array[ ], char value)
static <T> int binarySearch(T[ ] array, T value, Comparator<? super T> c)
CopyOf
static char[ ] copyOf(char[ ] source, int len)
static <T,U> T[ ] copyOf(U[ ] source, int len, Class<? extends T[ ]> resultT)
CopyOfRange
static char[ ] copyOfRange(char[ ] source, int start, int end)
static <T,U> T[ ] copyOfRange(U[ ] source, int start, int end, Class<? extends T[ ]> resultT)
equals
static boolean equals(char array1[ ], char array2 [ ])
static boolean deepEquals(Object[ ] a, Object[ ] b) // nested arrays
Algo - Sort
static void sort(int array[ ])
static <T> void sort(T array[ ], Comparator<? super T> c)
static void parallelSort(int array[ ])
static <T> void parallelSort(T array[ ], Comparator<? super T> c)
Stream
static DoubleStream stream(double array[ ])
static IntStream stream(int array[ ])
static LongStream stream(long array[ ])
static <T> Stream stream(T array[ ])
Split Iterator
static Spliterator.OfDouble spliterator(double array[ ])
static Spliterator.OfInt spliterator(int array[ ])
static Spliterator.OfLong spliterator(long array[ ])
static <T> Spliterator spliterator(T array[ ])
Util Methods
toString()
deepToString()
hashCode()
deepHashCode()
IntToDoubleFunction<? extends T> genVal)
IntToDoubleFunction<? extends T> genVal)
static void parallelPrefix(double array[ ], DoubleBinaryOperator func)
copyOf( )
- longer than source, default padding 0, null ,false.
- In the last form, the type of resultT becomes the type of the array returned.
- If len is negative, a NegativeArraySizeException is thrown.
- If source is null, a NullPointerException is thrown.
- If resultT is incompatible with the type of source, an ArrayStoreException is thrown.
copyOfRange( )
- If start is negative or greater than the length of source, an ArrayIndexOutOfBoundsException is thrown.
- If start is greater than end, an IllegalArgumentException is thrown.
- If source is null, a NullPointerException is thrown.
- If resultT is incompatible with the type of source, an ArrayStoreException is thrown.
Collections.sort algorithm
What sorting algorithm is used by Java’s Collections.sort(), and why?
- Merge sort - fast, stable sorting, O(n log(n)). For Object References.
- Merge sort requires additional scratch space proportional to the size of the input array.
- Quicksort - primitive values, have no identity.
- Uses Tim Sort - stable, adaptive, iterative mergesort, O(n logn) time (worst case).
- Tim Sort is also called hybrid Sort, Insertion Sort + Modified Merge Sort.
- Timsort uses insertion sort for very small amounts of data (more efficient for n < N, threshold).
- Modified Mergesort - used by java.util.Arrays.sort and (indirectly) by java.util.Collections.sort for object references.
- Here, merge is omitted if highest(low sublist) < lowest(high sublist) java 7, Sort used tim sort algorithm which is mixture off merge sort and the binary search and it is also called the hybrid sort because it can sort all the datatype. Tim sort has o (n) running time in worst case but it comes under sequential sort algorithm in java.
Java 8, Sort used parallel sort algorithm on the basis of the granularity of the array or the size of array
- Best for data as large as 1 million
- Lower than granularity, sort by using dual pivot sort.
- Higher than granularity, sort by other type of sorting
- Java 8 sort algorithm work on the fork/join framework which used work stealing algorithm to sort.
public static void parallelSort(double[] a) {
int n = a.length, p, g;
if (n <= MIN_ARRAY_SORT_GRAN || (p = ForkJoinPool.getCommonPoolParallelism()) == 1)
DualPivotQuicksort.sort(a, 0, n - 1, null, 0, 0);
else
new ArraysParallelSortHelpers.FJDouble.Sorter(null, a, new double[n], 0, n, 0, ((g = n / (p << 2)) <= MIN_ARRAY_SORT_GRAN) ? MIN_ARRAY_SORT_GRAN : g).invoke();
}
- Minimum granularity, java.util.Arrays.MIN_ARRAY_SORT_GRAN = 8192 [0x2000])
-
Array length < minimum granularity, sorted using the DualPivotQuicksort.sort directly instead of the sorting task partition. Typically, using smaller sizes results in memory contention across tasks that makes parallel speedups unlikely. ForkJoinPool.getCommonPoolParallelism()returns the targeted parallelism level of the common pool- by default, equal to the number of available processors Runtime.getRuntime().availableProcessors().
- If your machine has only 1 worker thread, it will not use parallel task either.
When the array length reaches a minimum granularity and you got more than 1 worker thread, the array is sorted using the parallel sort method. And the ForkJoin common pool is used to execute parallel tasks.
Legacy Classes
- Legacy classes are supported due to legacy code still in use.
- All the legacy classes are synchronized.
- Use Collections class to get synchronized version.
- Legacy classes
- Enumeration - Legacy interface. superseded by Iterator.
- Dictionary
- Hashtable
- Properties
- Stack
- Vector
Enumeration Interface
- To enumerate (obtain one at a time) the elements in a collection of objects.
- Used with Legacy classes (Vector, Properties) and several other API classes.
- throws NoSuchElementException when enumeration is complete.
boolean hasMoreElements()
E nextElement()
Vector
- Vector - dynamic array, synchronized
- Vector is reengineered to extend AbstractList and to implement List and Iterable.
- Now, Vector can have its contents iterated by the enhanced for loop.
- protected int capacityIncrement: how much to increase on resized, default doubled.
- protected int elementCount
- protected Object[] elementData
- Automatically allocates extra room for additional objects, reduces allocation cycles.
Vector( )
Vector(int size)
Vector(int size, int incr)
Vector(Collection<? extends E> c)
| void addElement(E element) | E lastElement( ) |
| int capacity( ) | int lastIndexOf(Object element) |
| Object clone( ) | int lastIndexOf(Object element, int start) |
| boolean contains(Object element) | void removeAllElements( ) |
| void copyInto(Object array[ ]) | boolean removeElement(Object element) |
| E elementAt(int index) | void removeElementAt(int index) |
| Enumeration | void setElementAt(E element, int index) |
| void ensureCapacity(int size) | void setSize(int size) |
| E firstElement( ) | int size( ) |
| int indexOf(Object element) | String toString( ) |
| int indexOf(Object element, int start) | void trimToSize( ) |
| void insertElementAt(E element, int index) | boolean isEmpty( ) |
Stack
- Stack is a subclass of Vector that implements a standard last-in, first-out stack.
- EmptyStackException is thrown in case of stack underflow.
- Stack includes all the methods defined by Vector and adds several of its own.
- One other point: although Stack is not deprecated, ArrayDeque is a better choice.
| Methods | ||||
|---|---|---|---|---|
| boolean empty( ) | E pop( ) | E peek( ) | E push(E element) | int search(Object element) |
Dictionary
- Abstract class represents key/value storage repository and operates much like Map.
- Dictionary is classified as obsolete, because it is fully superseded by Map.
| Methdos | |||
|---|---|---|---|
| Enumeration | Enumeration | V get(Object key) | V remove(Object key) |
| boolean isEmpty() | int size( ) | V put(K key, V value) |
Hashtable
Hashtable( )
Hashtable(int size)
Hashtable(int size, float fillRatio)
Hashtable(Map<? extends K, ? extends V> m)
- Hashtable was implementation of a Dictionary.
- Hashtable was reengineered to also implement the Map interface.
- It is similar to HashMap, but is synchronized.
- Neither keys nor values can be null, NullPointerException.
- Key is hashed, and hash code is used as the index at which the value is stored within the table.
- A hash table takes objects that override the hashCode( ) and equals( ) methods of Object.
- The default size is 11.
- Default fill Ratio is 0.75.
| Methods | ||
|---|---|---|
| void clear( ) | Enumeration | void rehash( ) |
| Object clone( ) | V get(Object key) | V remove(Object key) |
| boolean contains(Object value) | boolean isEmpty( ) | int size( ) |
| boolean containsKey(Object key) | Enumeration | String toString( ) |
| boolean containsValue(Object value) | V put(K key, V value) |
Properties
- Properties is a subclass of Hashtable.
- key and values are both String.
- It is the type of object returned by System.getProperties( ).
- This variable holds a default property list associated with a Properties object.
- Constructors: Properties( ) , Properties(Properties propDefault) - In both cases, the property list is empty.
- Properties also contains one deprecated method: save( ) now replaced by store( ) as save( ) did not handle errors correctly.
| String getProperty(String key) |
| String getProperty(String key, String defaultProperty) |
| void list(PrintStream streamOut) |
| void list(PrintWriter streamOut) |
| void load(InputStream streamIn) throws IOException |
| void load(Reader streamIn) throws IOException |
| void loadFromXML(InputStream streamIn) throws IOException, InvalidPropertiesFormatException |
| Enumeration<?> propertyNames( ) |
| Object setProperty(String key, String value) |
| void store(OutputStream streamOut, String description) throws IOException |
| void store(Writer streamOut, String description) throws IOException |
| void storeToXML(OutputStream streamOut, String description) throws IOException |
| void storeToXML(OutputStream streamOut, String description, String enc) |
| Set |
- When you construct a Properties object, you can pass another instance of Properties to be used as the default properties for the new instance. In this case, if you call getProperty(“foo”) on a given Properties object, and “foo” does not exist, Java looks for “foo” in the default Properties object. This allows for arbitrary nesting of levels of default properties.
Using store( ) and load( )
One of the most useful aspects of Properties is that the information contained in a Properties object can be easily stored to or loaded from disk with the store( ) and load( ) methods. At any time, you can write a Properties object to a stream or read it back.
Properties ht = new Properties();
FileInputStream fin = new FileInputStream("phonebook.dat");
ht.load(fin);
ht.put("name","myName");
FileOutputStream fout = new FileOutputStream("phonebook.dat");
ht.store(fout, "Telephone Book");
Concurrent Collection Classes
CopyOnWriteArrayList
- Thread safe variant of ArrayList.
- mutative operations like add, set are implemented by creating a fresh copy of the underlying array.
- Doesn’t throw currentModificationException.
- Allows null.
BlockingQueue
- Primarily used for implementing producer consumer problem.
- Producer - wait till space is available while adding.
- Consumer – wait till queue becomes non empty while removing.
- Java implementations - ArrayBlockingQueue, LinkedBlockingQueue, PriorityBlockingQueue, SynchronousQueue etc.
- BlockingQueue implementations are thread-safe and can also be used in inter-thread communications.
- null is not allowed.
ConcurrentHashMap
- ConcurrentHashMap utilizes the same principles of HashMap, but for a multi-threaded application.
- It does not require explicit synchronization.
- Hashtable provides concurrent access to the Map.Entries by locking the entire map. Hence performance is impacted.
- Provides the same functionality as of Hashtable but with a performance comparable to HashMap.
- Bucket/Segment Level Lock rather than Object Level.
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
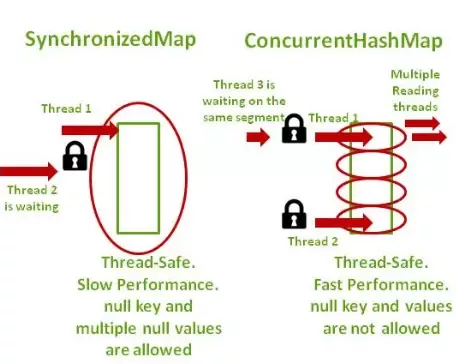
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)
| initialCapacity | initial capacity, by default 16. |
| concurrencyLevel | estimated number of concurrently updating threads, by default 16. |
- By default, ConcurrentHashMap maintains 16 locks for 16 buckets of the Map.
- At max 16 threads (concurrency level) can modify the collection at the same time, if each thread works on different bucket.
- get() do not block, so may overlap with update operations (put and remove).
- Retrievals reflect the results of the most recently completed update operations holding upon their onset.
- Ideally, you should choose a value to accommodate as many threads as will ever concurrently modify the table. Using a significantly higher value than you need can waste space and time, and a significantly lower value can lead to thread contention.
HashTable vs ConcurrentHashMap
| HashTable | ConcurrentHashMap | |
|---|---|---|
| Lock | Object Level | Bucket Level Lock for write |
| Concurrent Reads | No, get() method is synchronized | Allowed, by using volatile keyword |
Why does Java provide default value of partition count as 16 instead of very high value?
- Ideally, you should choose a value to accommodate as many threads as will ever concurrently modify the table.
- Using a significantly higher value than you need can waste space and time
- a significantly lower value can lead to thread contention.
Write the simple example which proves ConcurrentHashMap class behaves like fail safe iterator?
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample{
public static void main(String[] args) {
ConcurrentHashMap<String,String> premiumPhone = new ConcurrentHashMap<>();
premiumPhone.put("Apple", "iPhone6");
Iterator iterator = premiumPhone.keySet().iterator();
while (iterator.hasNext()) {
System.out.println(premiumPhone.get(iterator.next()));
premiumPhone.put("Sony", "Xperia Z");
}
}
}
Output : iPhone6
When is ConcurrentHashMap a better choice?
- ConcurrentHashMap is a better choice when there are more reads than writes.
- If there are more writes and that too many threads operating on the same segment then the threads will block which will deteriorate the performance.
Concurrent Collection FAQ
Which collection classes are thread-safe?
- Vector, Hashtable, Properties, Stack.
- Concurrent API allows modification of collection while iteration because they work on the clone of the collection.
What are concurrent Collection Classes?
- java.util.concurrent contains thread-safe collection classes that allow collections to be modified while iterating.
- Java.util - Iterator implementation are fail-fast and throw ConcurrentModificationException.
- java.util.concurrent - Iterator implementation is fail-safe and we can modify the collection while iterating.
- exmaples - CopyOnWriteArrayList, ConcurrentHashMap, CopyOnWriteArraySet.
How can we create a synchronized collection from given collection?
Collections.synchronizedCollection(Collection c)
Can two threads update the ConcurrentHashMap simultaneously?
- Yes, if on different buckets/segments.
- No, if on same bucket/segment.
Why ConcurrentHashMap does not allow null keys and null values?
- Not allowed due to ambiguities in ConcurrentHashMaps, ConcurrentSkipListMaps.
- map.get(key) returns null, can’t find if value is null or the key isn’t mapped.
- In non-concurrent map, map.contains(key) can be used, but in a concurrent one, the map might have changed between calls.
- key k might be deleted in between the get(k) and containsKey(k) calls.
if (map.containsKey(k))
return map.get(k);
else
throw new KeyNotPresentException();
TODO
- Use cases for IdentityHashMap
- Weak HashMap internals
- concurrent.ConcurrentHashMap
- collections.SynchronizedMap
- HashMap
- HashTable
- IdentityHashMap
- EnumMap
- WeakHashMap
- LinkedHashMap
- TreeMap
- concurrent.ConcurrentSkipListMap