- Introduction
- Producer
- Consumer
- Schema Evolution (Avro Schemas)
- ToDo
Introduction
Apache Kafka® is a distributed streaming platform. What exactly does that mean?
A streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
What it can do?
- Can be used as an Enterprise messaging system.
- Can be used for stream processing.
- Provides connectors to import and export bulk data from DB and other systems.
Kafka is generally used for two broad classes of applications
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
First a few concepts
- Kafka is run as a cluster on one or more servers that can span multiple datacenters.
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
Kafka is
- being used as big data streaming.
- scalable platform in terms of storing data and processing capacity.
- highly available
- popular for exactly once kind of scenarios, critical for financial domains.
Kafka vs Queue
How is it different from Queue like ActiveMQ?
- Kafka stores client offset, this capacity is not available in ActiveMQ.
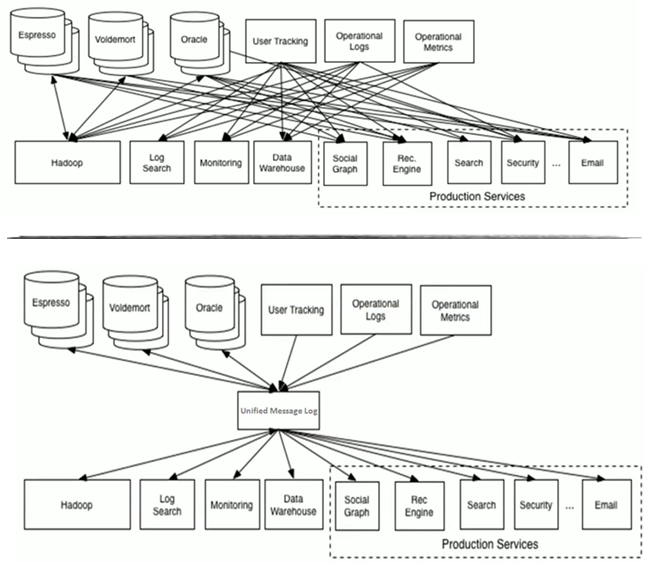
Integration Problem
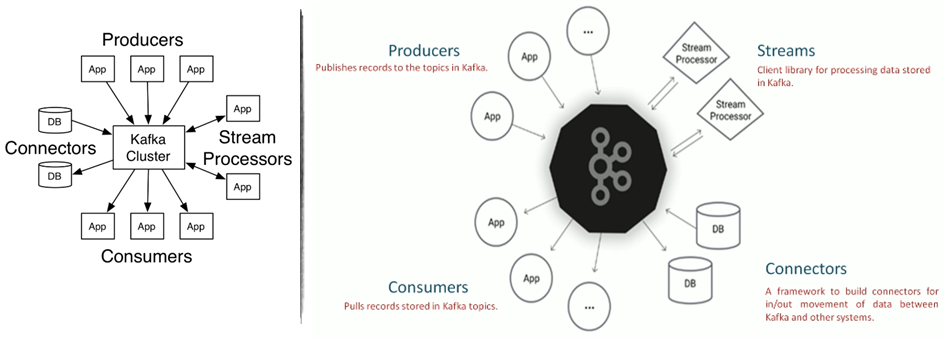
Core APIs
- Producer API allows an application to publish a stream of records to one or more Kafka topics.
- Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
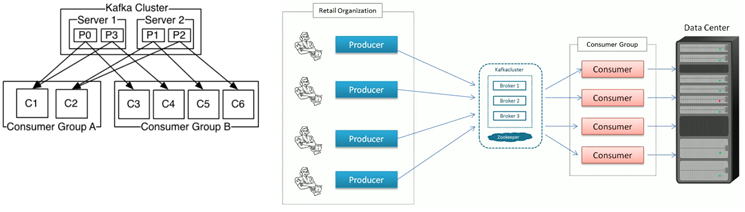
Core Concepts
- Producer: Application sending messges to Kafka. (Array of bytes)
- Consumer: Application reading data from kafka.
- Broker: Kafka server
- Cluster: A group of computers sharing workload, running 1 instance of broker). Distributed system.
- Topic: Unique name for kafka stream.
- Partitions: Breaking huge data that is larger than single broker capacity. Each partition sits on a single machine, you cannot break it further.
- Offset: Sequence id given to messages as they arrive in a partition. (Immutable).
- No global offset for partitions, it’s local to a partition.
- Consumer groups:
- Group of consumers sharing workload.
- Maximum consumers in group = number of partitions of the topic.
- No more than 2 consumers are allowed by kafka to read simultaneously to avoid double reading of records.

Kafka CLI
- URL - https://kafka.apache.org/quickstart
- bin\windows\ instead of bin/, and change the script extension to .bat.
// Unzip tar file
tar -xzf kafka_2.11-2.1.0.tgz
cd kafka_2.11-2.1.0
Start Stop Zookeeper
bin\windows\zookeeper-server-start.bat config/zookeeper.properties
bin\windows\zookeeper-server-stop.bat
Start Kafka Cluster
bin\windows\kafka-server-start.bat config/server.properties
bin\windows\kafka-server-stop.bat
Create Topics
bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic naruto
bin\windows\kafka-topics.bat --list --zookeeper localhost:2181
bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Dashboard Describe
bin\windows\kafka-topics.bat --describe --zookeeper localhost:2181 --topic my-replicated-topic
Single Broker Cluster Consumer-Producer
bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic naruto
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic naruto --from-beginning
Multiple Broker Cluster
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-2
bin/kafka-server-start.sh config/server-1.properties
bin/kafka-server-start.sh config/server-2.properties
Kafka Broker Configuration
| Broker Configuration | |
|---|---|
| broker.id | id of broker |
| port | port on which broker runs, needs to be changed if more than 1 broker is on same machine. |
| log.dirs | directory where logs for the broker will be published. |
| zookeeper.connect | zookeeper address, necessary to form a clusture. |
| delete.topic.enable | Default false. Required for Dev environments. topic management tool. |
| auto.create.topics.enable | Default false. Required for Dev environments. Non-existing topic gets created if something published on such topic. |
| default.replication.factor | Default value is 1. |
| num.partitions | Default value is 1. |
| log.retention.ms | Deafault 7 days. Older messages get deleted from kafka. |
| log.retention.bytes | Partition size for cleanup activity. Applicable to partition only. |
Fault Tolerance
Enabling a system to continue operating properly in the event of the failure of some of its components.
Replication factor
- Number of total copies of a pertition.
- 3 is a reasonable number
- Replication factor is set at a topic level
Replica created as Leader and Follower.
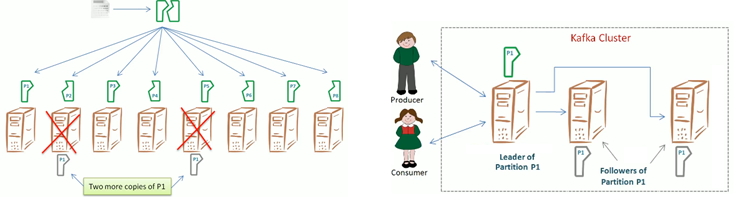
Different server.properties used for each broker
- broker.id=0
- log.dirs
- broker port (1 machine for multiple brokers)
ISR
- in-sync replicas
- synced with leader.
Producer
- bootstrap.servers = brokers list for zookeeper
- Key.serializer
- Value.serializer
KafkaProducer send(ProducerRecord<K,V> record) returns Future
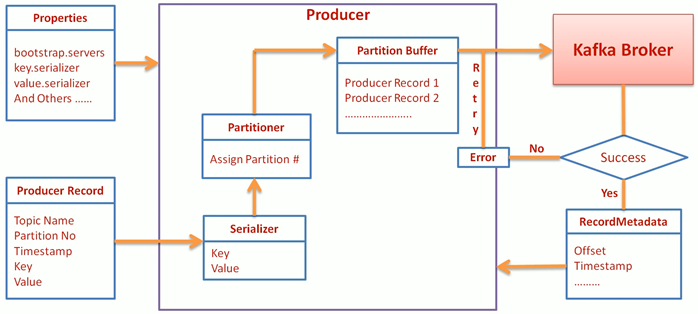
- Asynchronous Producer (Better throughput than fire-and-forget).
- max.in.flight.requests.per.connection = number of in-flight messages sent to cluster without an acknowledgement.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092, localhost:9093");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new KafkaProducer<>(topic, key, value);
producer.send(record, new MyProducerCallback());
Class MyProducerCallback implements Callback{
@Override
Public void onCompletion(RecordMetadata recordMetadata, Exception e){
If(e != null){ Sysout("AsynchronousProducer falied with exception"); }
}
}
Partitioner
Default Partitioner
- If partition number specified, use it.
- If key specified without partition number, choose partition as per hash of the key.
- If none of the above, assign partition in round-robin fashion.
- return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
Custom Partitioner
props.put("partitioner.class", "SensorPartitioner");
props.put("speed.sensor.name", "TSS"); ------------------------> Custom property, not provided by kafka
public class SensorPartitioner implements Partitioner {
// First 30% for specific partition
private String speedSensorName;
public void configure(Map < String, ? > configs) {
speedSensorName = configs.get("speed.sensor.name").toString();
}
public int partition(String topic, Object key, byte[] keyBytes, Object value,
byte[] valueBytes, Cluster cluster) {
List < PartitionInfo > partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
int sp = (int) Math.abs(numPartitions * 0.3);
int p = 0;
if ((keyBytes == null) || (!(key instanceof String)))
throw new InvalidRecordException("All messages must have string key");
if (((String) key).equals(speedSensorName))
// key is same hence hashing the value for partition number
p = Utils.toPositive(Utils.murmur2(valueBytes)) % sp;
else
p = Utils.toPositive(Utils.murmur2(keyBytes)) % (numPartitions - sp) + sp;
System.out.println("Key = " + (String) key + " Partition = " + p);
return p;
}
public void close() {}
}
Custom Serializers
- props.put(“value.serializer”, “SupplierSerializer”);
- Generic serializers: avro or protocol-buffer
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.errors.SerializationException;
import java.io.UnsupportedEncodingException;
import java.util.Map;
import java.nio.ByteBuffer;
public class SupplierSerializer implements Serializer < Supplier > {
private String encoding = "UTF8";
@Override
public void configure(Map < String, ? > configs, boolean isKey) {
// nothing to configure
}
@Override
public byte[] serialize(String topic, Supplier data) {
int sizeOfName;
int sizeOfDate;
byte[] serializedName;
byte[] serializedDate;
try {
if (data == null)
return null;
serializedName = data.getName().getBytes(encoding);
sizeOfName = serializedName.length;
serializedDate = data.getStartDate().toString().getBytes(encoding);
sizeOfDate = serializedDate.length;
ByteBuffer buf = ByteBuffer.allocate(4 + 4 + sizeOfName + 4 + sizeOfDate);
buf.putInt(data.getID());
buf.putInt(sizeOfName);
buf.put(serializedName);
buf.putInt(sizeOfDate);
buf.put(serializedDate);
return buf.array();
} catch (Exception e) {
throw new SerializationException("Error when serializing Supplier to byte[]");
}
}
@Override
public void close() {
// nothing to do
}
}
import java.nio.ByteBuffer;
import java.util.Date;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.serialization.Deserializer;
import java.io.UnsupportedEncodingException;
import java.util.Map;
public class SupplierDeserializer implements Deserializer < Supplier > {
private String encoding = "UTF8";
@Override
public void configure(Map < String, ? > configs, boolean isKey) {
//Nothing to configure
}
@Override
public Supplier deserialize(String topic, byte[] data) {
try {
if (data == null) {
System.out.println("Null recieved at deserialize");
return null;
}
ByteBuffer buf = ByteBuffer.wrap(data);
int id = buf.getInt();
int sizeOfName = buf.getInt();
byte[] nameBytes = new byte[sizeOfName];
buf.get(nameBytes);
String deserializedName = new String(nameBytes, encoding);
int sizeOfDate = buf.getInt();
byte[] dateBytes = new byte[sizeOfDate];
buf.get(dateBytes);
String dateString = new String(dateBytes, encoding);
DateFormat df = new SimpleDateFormat("EEE MMM dd HH:mm:ss Z yyyy");
return new Supplier(id, deserializedName, df.parse(dateString));
} catch (Exception e) {
throw new SerializationException("Error when deserializing byte[] to Supplier");
}
}
@Override
public void close() {
// nothing to do
}
}
Producer Config
bootstrap.servers
- list of kafka broker url with port number.
- necessary for producer to have connection with kafka clusture.
props.put("bootstrap.servers", "localhost:9092, localhost:9093");
key.serializer
- props.put(“key.serializer”, “org.apache.kafka.common.serialization.StringSerializer”);
value.serializer
- props.put(“value.serializer”, “org.apache.kafka.common.serialization.StringSerializer”);
partitioner.class
- For custom partitioner
- props.put(“partitioner.class”, “SensorPartitioner”);
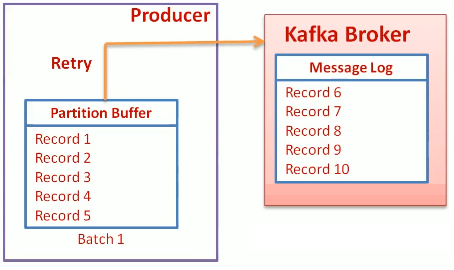
acks
- 0 – Producer doesn’t wait for response.
- Possible loss of messages
- High Throughout
- No Retries
- 1 – Producer waits for the response from leader
- Response as soon as leader receives the message, before replication.
- Possible to lose message if leader breaks before making replica.
- Not 100% reliable
- all – Leader sends acknowledgement once all live replicas are in sync
- highest reliability
- highest latency
- here we can use asynchronous call
retries
- Defies number of times of retry for failure case.
- Default value is 0
- retry.backoff.ms – time between retries, default 100 ms.
max.in.flight.requests.per.connection
- number of messages allowed to sent without any acknowledgement, i.e. in-flight.
- Bigger number increases throughput bult also bumps up the memory usage.
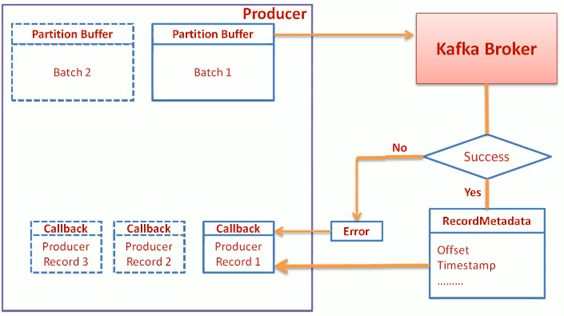
buffer.memory
compression.type
batch.size
linger.ms
client.id
max.request.size
Asynchronous Call (Caution)
- It may happen that due to retries, the sequence of messages sent to kafka are mixed up.
- For the cases where sequence is critical, either use
- Synchronous send
max.in.flight.requests.per.connection=1
Consumer
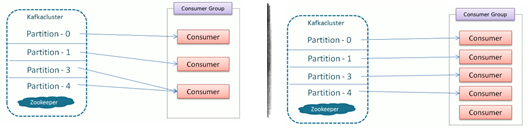
- Consumer Groups are used to read and process the data in parallel for an application.
- Max active consumers in a group = no. of partitions.
- Partitions are never shared among the members of same group at the same time.
- Group coordinator maintains a list of active consumers.
- Rebalance is initiated when the list of consumers is modified.
- Group Leader executes a rebalance activity.
Consumer group co-ordinator is one of broker while group leader is one of consumer in consumer group.
Group co-ordinator is nothing but one of brokers which receives heartbeats(or polling for message) from all consumers of a consumer group. Every consumer group has a group coordinator. If consumer stops sending heartbeats, coordinator will trigger rebalance.
When a consumer wants to join a consumer group, it sends a JoinGroup request to the group coordinator. The first consumer to join the group becomes the group leader. The leader receives a list of all consumers in the group from the group coordinator (this will include all consumers that sent a heartbeat recently and are therefore considered alive) and it is responsible for assigning a subset of partitions to each consumer. It uses an implementation of PartitionAssignor interface to decide which partitions should be handled by which consumer. After deciding on the partition assignment, the consumer leader sends the list of assignments to the GroupCoordinator which sends this information to all the consumers. Each consumer only sees his own assignment - the leader is the only client process that has the full list of consumers in the group and their assignments. This process repeats every time a rebalance happens.
The coordinator is responsible for managing the state of the group. Its main job is to mediate partition assignment when new members arrive, old members depart, and when topic metadata changes. The act of reassigning partitions is known as rebalancing the group.
When a group is first initialized, the consumers typically begin reading from either the earliest or latest offset in each partition. The messages in each partition log are then read sequentially. As the consumer makes progress, it commits the offsets of messages it has successfully processed. For example, in the figure below, the consumer’s position is at offset 6 and its last committed offset is at offset 1.
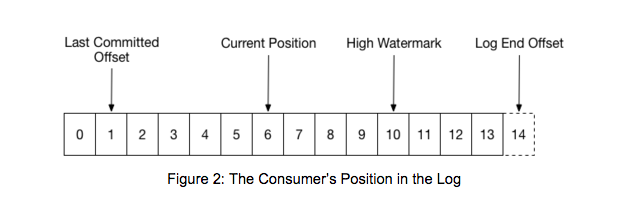
When a partition gets reassigned to another consumer in the group, the initial position is set to the last committed offset. If the consumer in the example above suddenly crashed, then the group member taking over the partition would begin consumption from offset 1. In that case, it would have to reprocess the messages up to the crashed consumer’s position of 6.
The diagram also shows two other significant positions in the log. The log end offset is the offset of the last message written to the log. The high watermark is the offset of the last message that was successfully copied to all of the log’s replicas. From the perspective of the consumer, the main thing to know is that you can only read up to the high watermark. This prevents the consumer from reading unreplicated data which could later be lost.
Consumer Config
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "consumer-tutorial");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
we need to configure an initial list of brokers for the consumer to be able discover the rest of the cluster. This doesn’t need to be all the servers in the cluster—the client will determine the full set of alive brokers from the brokers in this list.
consumer.subscribe(Arrays.asList("foo", "bar"));
After you have subscribed, the consumer can coordinate with the rest of the group to get its partition assignment. it is not possible to mix automatic and manual assignment. The subscribe method is not incremental: you must include the full list of topics that you want to consume from. You can change the set of topics you’re subscribed to at any time–any topics previously subscribed to will be replaced by the new list when you call subscribe.
After subscribing to a topic, you need to start the event loop to get a partition assignment and begin fetching data. It sounds complex, but all you need to do is call poll in a loop and the consumer handles the rest. Each call to poll returns a (possibly empty) set of messages from the partitions that were assigned.
try {
while (running) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records)
System.out.println(record.offset() + ": " + record.value());
}
} finally {
consumer.close();
}
The poll API returns fetched records based on the current position. When the group is first created, the position will be set according to the reset policy (which is typically either set to the earliest or latest offset for each partition). Once the consumer begins committing offsets, then each later rebalance will reset the position to the last committed offset. The parameter passed to poll controls the maximum amount of time that the consumer will block while it awaits records at the current position. The consumer returns immediately as soon as any records are available, but it will wait for the full timeout specified before returning if nothing is available.
You should always close the consumer when you are finished with it. Not only does this clean up any sockets in use, it ensures that the consumer can alert the coordinator about its departure from the group.
- heartbeat.interval.ms
- session.timeout.ms
Offsets
- Current Offset
- Current offset for the consumer.
- committed offset
- consumer confirms to consumer group that the records are read successfully for the partition till this offset.
- Important in case of repartition, new consumer will start after committed offset.
Commit Current Offset
- AUTO COMMIT
- enable.auto.commit – Default true
- Auto.commit.interval.ms – Default 5 sec.
- Chances of double-reading are there.
- MANUAL COMMIT
- consumer.commitSync() - blocking
- consumer.commitAsync() – non blocking and no retry.

Commit Specific Offset
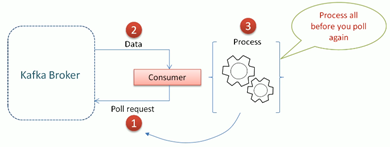
Issues
- Delay in next poll.
- Rebalance is triggered.
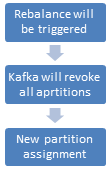
RebalanceListener
HOW TO KNOW THAT A REBALANCE IS TRIGGERED?
- Consumer RebalanceListener
- onPartitionsRevoked() -
- onPartitionsAssigned() – called after partition is assigned and before reading of messages start.
Responsibilities of ConsumerRebalanceListener
- Maintain a list of offsets that are processed and ready to be committed.
- Commit the offsets when partitions are going away.
RebalanceListner rebalanceListener = new RebalanceListner(consumer);
Consumer.subscribe(Arrays.asList(topics), rebalanceListener);
...
for(ConsumerRecord<String, String> record : records){
rebalanceListner.addOffset(record.topic(), record.partition(), record.offset())f
}
consumer.commitSync(rebalanceListner.getCurrentOffsets);
public class RebalanceListner implements ConsumerRebalanceListner{
private KafkaConsumer consumer;
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HasMap();
}
Things handled by kafka are
- Automatic group management and partition assignment
- Offset and consumer positions control.
Automatic Partition Assignment - You don’t know which partition goes to which consumer.
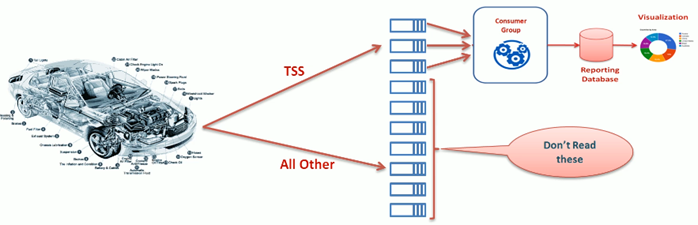
Commit in
- Range (first 3 partitions for example)
- Round Robin
Schema Evolution (Avro Schemas)
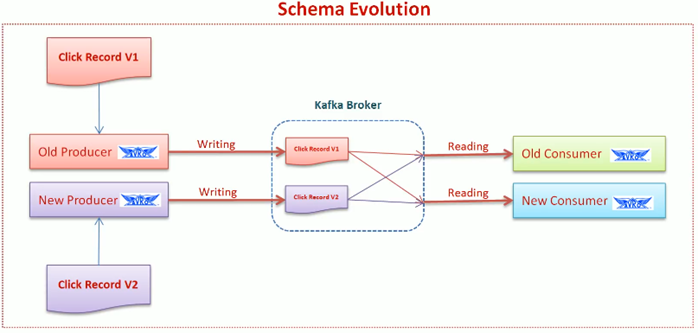
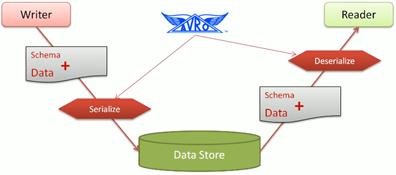
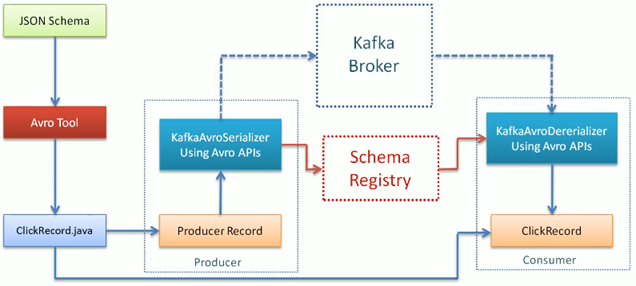
props.put("value.deserializer", "io.consfluent.kafka.serializers.KafkaAvroDeserializer");
props.put("schema.registry.url", "http://localhost:8081");
props.put("specific.avro.reader", "true");
- Confluent Platform Quickstart
- Confluent Platform – rpm packages by yum
- Schema resolution
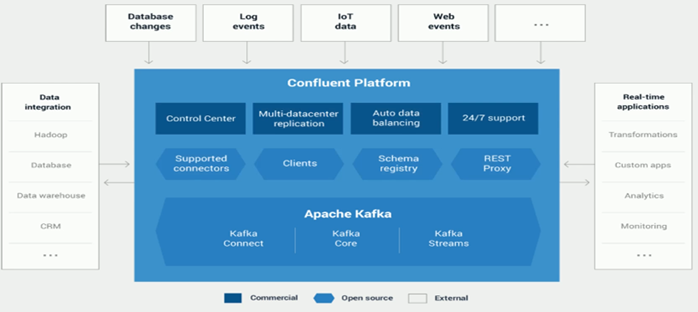
ToDo
