SQL
Table of contents
References
- Database Normalization
- ACID Properties
- DB Partitioning in Distributed Systems
- Types of indexes in DB
Introduction
- SQL is Structured Query Language, which is a computer language for storing, manipulating and retrieving data stored in relational DB.
- SQL is the standard language for Relation Database System.
- All Relational DBMS like MySQL, MS Access, Oracle, Sybase, Informix, postgres and SQL Server use SQL as standard database language.
- Also, they are using different dialects, such as:
- MS SQL Server using T-SQL,
- Oracle using PL/SQL,
- MS Access version of SQL is called JET SQL (native format) etc.
| Database | Collection of logically related data |
| DBMS | Set of software or program that enables storing, modifying and extracting info from the DB |
| Data Model | Representation of real-world situation aboutwhich data is to be collected and stored in DB. Represents logical relationship and data flow among different data elements. |
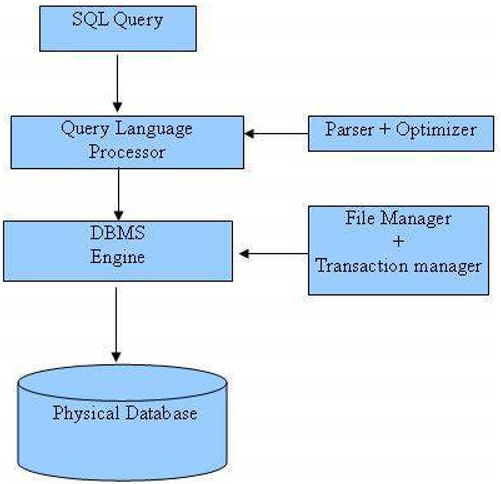
SQL Process
- When you are executing an SQL command for any RDBMS, the system determines the best way to carry out your request and SQL engine figures out how to interpret the task.
- There are various components included in the process. These components are Query Dispatcher, Optimization Engines, Classic Query Engine and SQL Query Engine, etc. Classic query engine handles all non-SQL queries but SQL query engine won’t handle logical files.
SQL Commands
- The standard SQL commands to interact with relational databases are CREATE, SELECT, INSERT, UPDATE, DELETE and DROP.
- Table - collection of related data entries as records(rows) having columns representing fields.
- What is NULL value? Aappears to be blank but is actually no value. It is different than a zero or spaces.
- These commands can be classified into groups based on their nature:
DML-Data Manipulation Language
CREATE
CREATE DATABASE database_name;
USE database_name;
CREATE TABLE table_name(col1 datatype, col2 datatype) PRIMARY KEY(col1, col4);
DESC table_name;
CREATE UNIQUE INDEX index_name ON table_name (col1,col2);
TRUNCATE
TRUNCATE TABLE <table_name>;
DROP
DROP DATABASE database_name;
DROP TABLE <table_name>;
ALTER
ALTER TABLE table_name {ADD|DROP|MODIFY} column_name {data_ype};
ALTER TABLE table_name DROP INDEX index_name;
ALTER TABLE <table_name> RENAME TO <new_table_name>;
INSERT
INSERT INTO table_name( column1, column2....columnN)
VALUES ( value1, value2....valueN);
UPDATE
UPDATE table_name SET col1 = v1, col2 = v2 [ WHERE CONDITION ];
DELETE
DELETE FROM table_name WHERE {CONDITION};
MERGE
TCL-Transaction Control Language
COMMIT
ROLLBACK
ROLLBACK;
SAVEPOINT
DQL-Data Query Language
SELECT
SELECT column1, column2....columnN
FROM table_name
WHERE column_name IN (val-1, val-2,...val-N)
OR column_name LIKE { AR% }
OR column_name BETWEEN val-1 AND val-2
ORDER BY column_name {ASC|DESC};
DCL-Data Control Language
GRANT
SQL Constraints
- Constraints are the rules enforced on data columns on table to limit the type of data that can go into a table.
- Ensures the accuracy and reliability of the data in the database.
- Constraints could be column level or table level.
- Following are commonly used constraints available in SQL:
- NOT NULL Constraint: Ensures that a column cannot have NULL value.
- DEFAULT Constraint: Provides a default value for a column when none is specified.
- UNIQUE Constraint: Ensures that all values in a column are different.
- PRIMARY Key: Uniquely identified each rows/records in a database table.
- FOREIGN Key: Uniquely identified a rows/records in any another database table.
- CHECK Constraint: The CHECK constraint ensures that all values in a column satisfy certain conditions.
- INDEX: Use to create and retrieve data from the database very quickly.
Data Integrity:
The following categories of the data integrity exist with each RDBMS:
- Entity Integrity: There are no duplicate rows in a table.
- Domain Integrity: Enforces valid entries for a given column by restricting the type, the format, or the range of values.
- Referential integrity: Rows cannot be deleted, which are used by other records.
- User-Defined Integrity: Enforces some specific business rules that do not fall into entity, domain or referential integrity.
SQL Syntax
- SQL is followed by unique set of rules and guidelines called Syntax.
- All the SQL statements start with any of the keywords like SELECT, INSERT, UPDATE, DELETE, ALTER, DROP, CREATE, USE, SHOW and all the statements end with a semicolon (;).
- Important point to be noted is that SQL is case insensitive, which means SELECT and select have same meaning in SQL statements, but MySQL makes difference in table names. So, if you are working with MySQL, then you need to give table names as they exist in the database.
- All the examples given in this tutorial have been tested with MySQL server.
SELECT-WHERE-AND/OR
SELECT column1, column2....columnN
FROM table_name
WHERE CONDITION-1 {AND|OR} CONDITION-2;
SQL DISTINCT Clause
SELECT
DISTINCT column1, column2....columnN
FROM table_name;
GROUP BY-HAVING
SELECT SUM(column_name)
FROM table_name
WHERE CONDITION
GROUP BY column_name
HAVING (arithematic function condition);
SQL COUNT Clause
SELECT COUNT(column_name)
FROM table_name
WHERE CONDITION;
FAQ
2nd highest salary of Employee?
--- ```sql select MAX(Salary) from Employee WHERE Salary NOT IN (select MAX(Salary) from Employee ); ```Max Salary from each department?
--- ```sql SELECT DeptID, MAX(Salary) FROM Employee GROUP BY DeptID. ``` print department name instead of department id, do LEFT or RIGHT OUTER JOIN to include departments without any employee as well. ```sql SELECT DeptName, MAX(Salary) FROM Employee e RIGHT JOIN Department d ON e.DeptId = d.DeptID GROUP BY DeptName; ```Find duplicate rows in a database? and then write SQL query to delete them?
--- ```sql SELECT * FROM emp a WHERE rowid = (SELECT MAX(rowid) FROM EMP b WHERE a.empno=b.empno) DELETE FROM emp a WHERE rowid != (SELECT MAX(rowid) FROM emp b WHERE a.empno=b.empno); ```Select employees who are also a manager?
--- ```sql SELECT e.name, m.name FROM Employee e, Employee m WHERE e.mgr_id = m.emp_id; ```You have a composite index of 3 columns, and WHERE clause has only mentioned 2 of them, Will Index be used for this operation?
--- ```sql SELECT * FROM Employee WHERE EmpId=2 and EmpFirstName='Radhe' ``` * Index is on EmpId, EmpFirstName, and EmpSecondName * If the given two columns are secondary index column then the index will not invoke, but if the given 2 columns contain the primary index(first column while creating index) then the index will invoke. In this case, Index will be used because EmpId and EmpFirstName are primary columns.Nth highest Salary
--- > Read full article for [nth highest salary](https://howtodoinjava.com/sql/sql-query-find-nth-highest-salary/) ```sql SELECT * FROM Employee_Test Emp1 WHERE ( n ) = ( SELECT COUNT( DISTINCT ( Emp2.Employee_Salary ) ) FROM Employee_Test Emp2 WHERE Emp2.Employee_Salary >= Emp1.Employee_Salary ) ``` #### How the query works * As we can see this query involves use of an inner query. Inner queries can be of two types. [**Correlated**](https://en.wikipedia.org/wiki/Correlated_subquery) and **uncorrelated** queries. Uncorrelated query is where inner query can run independently of outer query, and correlated query is where inner query runs in conjunction to outer query. Our ***nth highest salary*** is an example of `correlated query`. * Lest understand first that the inner query executes every time, a row from outer query is processed. Inner query essentially does not do any very secret job, it only return the count of distinct salaries which are higher than the currently processing row’s salary column. Anytime, it find that salary column’s value of current row from outer query, is equal to count of higher salaries from inner query, it returns the result. #### Performance analysis As we learned above that inner query executes every time, one row of outer query is processed, this brings a lot of performance overhead, specially if the number of rows are too big. To avoid this, one should use DB specific keywords to get the result faster. For example in SQL server, one can use key word TOP like this. ```sql SELECT TOP 1 EMPLOYEE_SALARY FROM ( SELECT DISTINCT TOP N EMPLOYEE_SALARY FROM EMPLOYEE_TEST ORDER BY EMPLOYEE_SALARY DESC ) A ORDER BY EMPLOYEE_SALARY WHERE N > 1 ```Order by last 3 chars
--- ```sql select name from STUDENTS where Marks>75 ORDER BY SUBSTR(NAME, -3, 3), ID; ```Difference between max and min population
--- ```sql select MAX_POP-MIN_POP FROM (select MAX(POPULATION) MAX_POP, MIN(POPULATION) AS MIN_POP from CITY); ```Print pattern 1
--- ``` * * * * * * * * * * * * * * * ``` ```sql DECLARE @var int -- Declare SELECT @var = 5 -- Initialization WHILE @var > 0 -- condition BEGIN -- Begin PRINT replicate('* ', @var) -- Print SET @var = @var - 1 -- decrement END -- END ```select max(avgsale) from (select avg(totalSale) as avgsale from Sales group by SalesPerson) as temp
SELECT GetDate();
SELECT ISDATE('1/08/13') AS "MM/DD/YY"; --> returns 0 because passed date is not in correct format
SELECT DISTINCT EmpName FROM Employees WHERE DOB BETWEEN ‘01/01/1960’ AND ‘31/12/1975’;
SELECT COUNT(*), sex from Employees WHERE DOB BETWEEN '01/01/1960' AND '31/12/1975' GROUP BY sex;
SELECT EmpName FROM Employees WHERE Salary>=10000;
SELECT * FROM Employees WHERE EmpName like 'M%';
SELECT * from Employees WHERE UPPER(EmpName) like '%JOE%';
SELECT YEAR(GETDATE()) as "Year";
SELECT student, marks from table where marks > SELECT AVG(marks) from table);
injection field value -> Paris’ OR ‘1=1
// Parameterized Query
SELECT * FROM Customers WHERE City = ('Paris' OR '1=1');
SQL Queries
MEDIAN
select round(median(lat_n),4) from station;
Queries
Query the greatest value of the Northern Latitudes (LAT_N) from STATION that is less than 137.2345 round the result to 4 places
select round(max(lat_n),4) from station where lat_n < 137.2345;
sum of all values in LAT_N, LONG_W rounded to a scale of 2 decimal places
select round(sum(lat_n),2), round(sum(long_w),2) from station;
Difference between total and distinct number of cities in station.
select count(*) - count(distinct city) from station;
Query the Western Longitude (LONG_W) for the largest Northern Latitude (LAT_N) in STATION that is less than 137.2345. Round your answer to 4 decimal places.
select round(long_w,4) from station where lat_n = (select max(lat_n) from station where lat_n < 137.2345);
find Manhattan Distance between two point with longitude and latitude with min and max values as point coordinates
- distance = |x2-x1|+|y2-y1|
select round(abs(a-c)+abs(b-d),4) from (select min(lat_n) a, min(long_w) b, max(lat_n) c, max(long_w) d from station);
find Eucledean Distance between two points in cartesian plane
select round(sqrt(power(a-c,2)+power(b-d,2)),4) from (select min(lat_n) a, min(long_w) b, max(lat_n) c, max(long_w) d from station);
Query the two cities in STATION with the shortest and longest CITY names, as well as their respective lengths (i.e.: number of characters in the name). If there is more than one smallest or largest city, choose the one that comes first when ordered alphabetically.
select * from (select city, length(city) cLength from station order by cLength, city) where rownum = 1
union
select * from (select city, length(city) cLength from station order by cLength desc, city) where rownum = 1;
Query the list of CITY names from STATION which have vowels (i.e., a, e, i, o, and u) as both their first and last characters. Your result cannot contain duplicates.
select distinct city from station
where substr(lower(city),1,1) in ('a','e','i','o','u')
and substr(lower(city), -1) in ('a','e','i','o','u');
select distinct city from station
where REGEXP_LIKE(lower(city), '^[aeiou].*[aeiou]$');
Query the list of CITY names from STATION that either do not start with vowels or do not end with vowels. Your result cannot contain duplicates.
- !a or !b –> !(a and b)
select distinct city from station where NOT REGEXP_LIKE(lower(city), '^[aeiou].*[aeiou]$');
select name||'('||substr(occupation,1,1)||')' from occupations order by name;
SELECT 'There are a total of '||COUNT(OCCUPATION)||' '||LOWER(OCCUPATION)||'s.' FROM OCCUPATIONS GROUP BY OCCUPATION ORDER BY COUNT(OCCUPATION) ASC, OCCUPATION ASC;
When Then Queries
query identifying the type of each record in the TRIANGLES table using its three side lengths. Output one of the following statements for each record in the table:
- Equilateral: It’s a triangle with all sides of equal length.
- Isosceles: It’s a triangle with 2 sides of equal length.
- Scalene: It’s a triangle with all sides of differing lengths.
- Not A Triangle: The given values of A, B, and C don’t form a triangle.
SELECT CASE WHEN A + B > C THEN CASE WHEN A = B AND B = C THEN 'Equilateral' WHEN A = B OR B = C OR A = C THEN 'Isosceles' WHEN A != B OR B != C OR A != C THEN 'Scalene' END ELSE 'Not A Triangle' END FROM TRIANGLES;
Print Pattern
https://www.geeksforgeeks.org/print-different-star-patterns-sql/
set @row := 0;
select repeat('* ', @row := @row + 1) from information_schema.tables
where @row < 5;
-- output
*
* *
* * *
* * * *
* * * * *
select rpad('*', 2*level-1, ' *') as c from dual connect by level <= 20 order by length(c) desc;
-- Output
* * * *
* * *
* *
*
select ceil(avg(salary)-avg(replace(salary,'0','')))
from employees e;
grade vs marks range in grades table
select (case
when grade <8
THEN NULL
ELSE name END) name, grade, marks
from
(
select name, grade, marks
from students, grades
where marks between min_Mark and Max_Mark
) gradeList
order by grade desc, name, coalesce(name,marks);